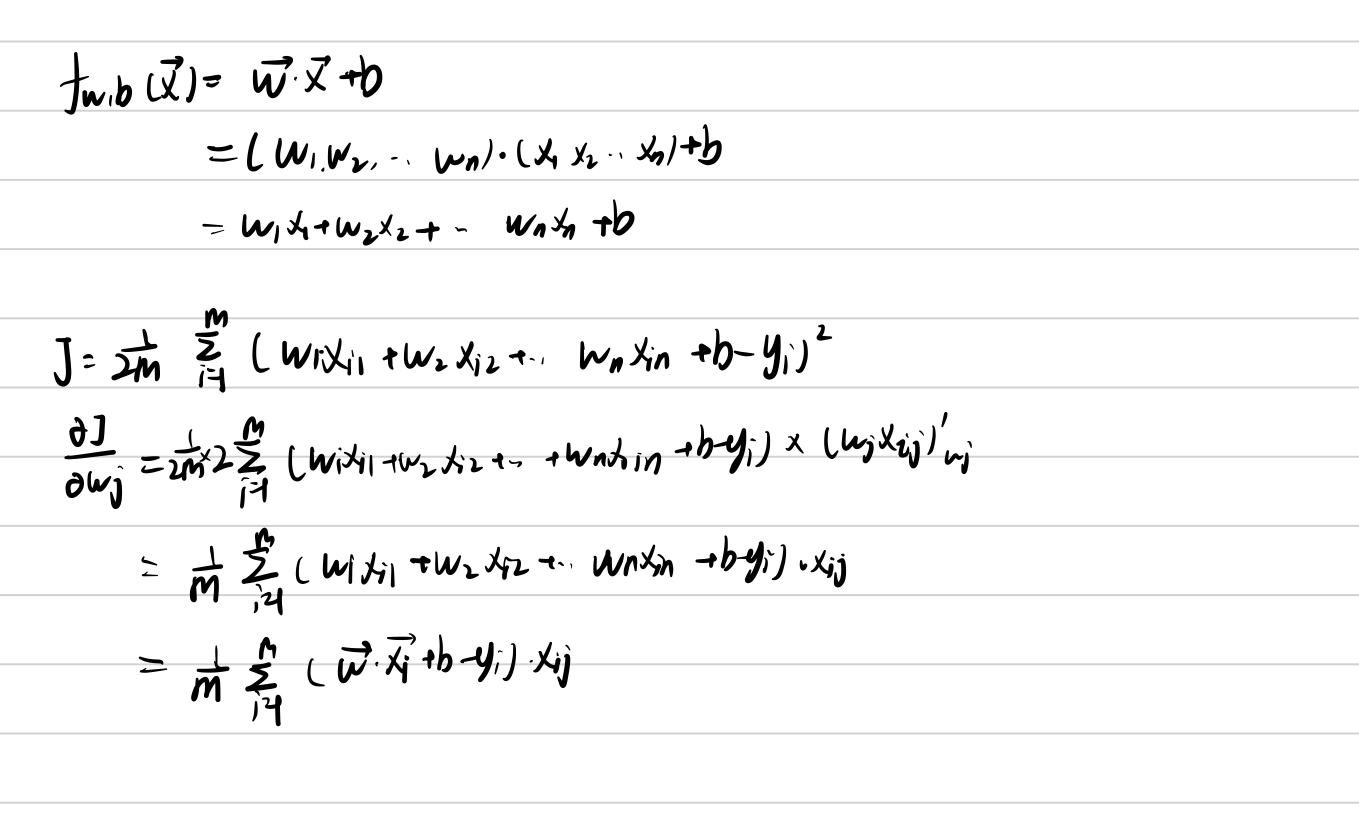多元线性回归
概述
特征:
拟合方程 :f ( x ⃗ ) = w ⃗ ⋅ x ⃗ + b f(\vec x)= \vec w \cdot \vec x+b f ( x ) = w ⋅ x + b
其中w ⃗ = [ w 1 , w 2 , w 3 . . . w n ] , x ⃗ = [ x 1 , x 2 . . . . x n ] \vec w=[w_{1},w_{2},w_{3}...w_{n}],\vec x =[x_{1},x_{2}....x_{n}] w = [ w 1 , w 2 , w 3 ... w n ] , x = [ x 1 , x 2 .... x n ]
w j = w j − α ⋅ α J α w j = w j − α ⋅ 1 m ∑ i = 1 m ( f w , b ( x i ) − y i ) x i j w_{j}=w_{j}-\alpha \cdot \frac{\alpha J}{\alpha w_{j}}=w_{j}-\alpha \cdot \frac{1}{m}\sum_{i=1}^{m}(f_{w,b}(x_{i})-y_{i})x_{ij} w j = w j − α ⋅ α w j α J = w j − α ⋅ m 1 ∑ i = 1 m ( f w , b ( x i ) − y i ) x ij
b = b − α ⋅ α J α b = b − α ⋅ 1 m ∑ 1 m ( f w , b ( x i ) − y i ) b=b-\alpha \cdot \frac{\alpha J}{\alpha b}=b-\alpha \cdot \frac{1}{m}\sum_{1}^{m}(f_{w,b}(x_{i})-y_{i}) b = b − α ⋅ α b α J = b − α ⋅ m 1 ∑ 1 m ( f w , b ( x i ) − y i )
m m m n n n
推导:
梯度下降法分类
批梯度下降(batch gradient descent)
计算出所有样本的误差之和再更新参数
w j = w j − ∑ i = 1 m ( f ( x ) − y ( i ) ) x j ( i ) w_{j}=w_{j}-\sum_{i=1}^{m}(f(x)-y^{(i)})x_{j}^{(i)} w j = w j − ∑ i = 1 m ( f ( x ) − y ( i ) ) x j ( i )
随机梯度下降(stochastic gradient descent)
计算出一个样本的误差就更新参数
f o r i = 1 t o m : for\space i=1\space to \space m: f or i = 1 t o m :
w j = w j − ( f ( x ) − y ( i ) ) x j ( i ) \space w_{j}=w_{j}-(f(x)-y^{(i)})x_{j}^{(i)} w j = w j − ( f ( x ) − y ( i ) ) x j ( i )
这种算法不一定保证能够收敛到损失函数的全局最优,但实践得出大部分情况下所得答案都和全局最优解近似
计算速度比批梯度下降法快,适用于数据量比较大的情况
梯度下降优化方法
特征压缩
思想:
注意到梯度下降法中每次迭代w j = w j − α ⋅ 1 m ∑ i = 1 m ( f w , b ( x i ) − y i ) x i j w_{j}=w_{j}-\alpha \cdot \frac{1}{m}\sum_{i=1}^{m}(f_{w,b}(x_{i})-y_{i})x_{ij} w j = w j − α ⋅ m 1 ∑ i = 1 m ( f w , b ( x i ) − y i ) x ij
其中w j 1 , w j 2 w_{j_{1}},w_{j_{2}} w j 1 , w j 2 x i j x_{ij} x ij
故考虑将每个特征的范围都压缩到范围基本一致的区间内
具体压缩方法:
x i : = x i − μ i m a x − m i n \begin{align} x_i :&= \dfrac{x_i - \mu_i}{max - min} \end{align}
x i : = ma x − min x i − μ i
x j ( i ) = x j ( i ) − μ j σ j μ j = 1 m ∑ i = 0 m − 1 x j ( i ) σ j 2 = 1 m ∑ i = 0 m − 1 ( x j ( i ) − μ j ) 2 \begin{align}
x^{(i)}_j &= \dfrac{x^{(i)}_j - \mu_j}{\sigma_j}\\
\mu_j &= \frac{1}{m} \sum_{i=0}^{m-1} x^{(i)}_j \\
\sigma^2_j &= \frac{1}{m} \sum_{i=0}^{m-1} (x^{(i)}_j - \mu_j)^2 \\
\end{align}
x j ( i ) μ j σ j 2 = σ j x j ( i ) − μ j = m 1 i = 0 ∑ m − 1 x j ( i ) = m 1 i = 0 ∑ m − 1 ( x j ( i ) − μ j ) 2
特征工程(当出现高次项即为多项式回归)
思想:
利用已有的特征组合推出新的特征加入到拟合方程中
例如已知房屋的长和宽,来预测价格。相比于f ( x ) = w 1 ∗ x 1 + w 2 ∗ x 2 f(x)=w_{1}*x_{1}+w_{2}*x_{2} f ( x ) = w 1 ∗ x 1 + w 2 ∗ x 2 x 3 = x 1 ∗ x 2 x_{3}=x_{1}*x_{2} x 3 = x 1 ∗ x 2 f ( x ) = w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 f(x)=w_{1}*x_{1}+w_{2}*x_{2}+w_{3}*x_{3} f ( x ) = w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3
Numpy
X=[[1,2],[3,4]],w=[1,2]
X@w=[ 1 ∗ 1 + 2 ∗ 2 , 3 ∗ 1 + 4 ∗ 2 ] = [ 5 , 11 ] [1*1+2*2,3*1+4*2]=[5,11] [ 1 ∗ 1 + 2 ∗ 2 , 3 ∗ 1 + 4 ∗ 2 ] = [ 5 , 11 ]
X*w(触发广播规则,w作用在X的每一行上)=[[1,4],[3,8]]
代码实现 :
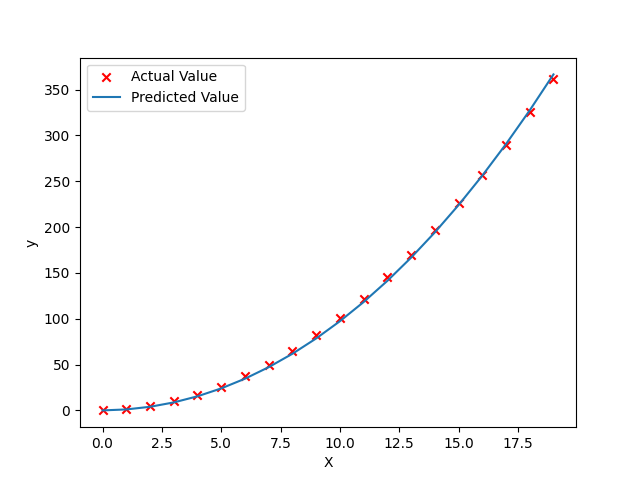
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import numpy as npimport matplotlib.pyplot as pltdef run_gradient (X,y,iter ,alpha ):0 ] 1 ] 0 0 for k in range (iter ):for j in range (n):0 for i in range (m):0 for i in range (m):for i in range (m):2 2 *m)return w,b,J_history0 ,20 ,1 )1 ,1 )2 , x**3 ] 1 + x**2 30000 ,1e-7 )print (w)print (b)'x' ,c='r' ,label='Actual Value' )"Predicted Value" )"X" ); plt.ylabel("y" ); plt.legend(); plt.show()
注意事项 :
由于代码中没有对X特征归一化,当学习率较高(>1e-7)时,python数据会爆,再一次说明了特征压缩的重要性
使用scikit-learn实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import SGDRegressorfrom sklearn.preprocessing import StandardScaler0 ,19 ,1 )1 ,1 )1 +x+x**2 print (f"{np.ptp(X_train,axis=0 )} " ) print (f"{np.ptp(X_norm,axis=0 )} " )1000 ) 1 ,2 ,figsize=(12 ,6 ),sharey=True )for i in range (len (ax)):'target' )'predict' )0 ].set_ylabel("Price" ); ax[0 ].legend()"target versus prediction using z-score normalized model" )