决策树
概览

决策树构建过程
- 不断选取一个特征作为判别节点,该特征使得划分后的两个branch的purity最大(即划分得最清晰)
熵
如何衡量一个集合中仅含两类示例的purity呢?这就需要引入熵的概念
熵用于衡量信息的混乱程度:
H(p)=−plogp — (1−p)log(1−p)
- note:为便于计算,我们定义′0log0′=0
扩展到多个类别:
H(x)=−∑i=1npilogpi

选择特征
如何选取特征呢?
-
设定问题背景:
假设数据集 D 中有 n 个样本,样本属于 k 个属性 {C1,C2,…,Ck},每个属性取值个数为N1,N2......Nk。对于每一个属性 Ci,我们希望计算其信息增益 IG(Ci),然后选择信息增益最大的属性作为当前节点的判别类别,其输出类别Y∈y1,y2
-
总体信息熵:
当前节点father 的信息熵 H(father) 为:
H(father)=−i=1∑kpilogpi
其中,pi 是类别 yi 在节点father 中的样本比例。
-
选取一个类别 C:
每次选取一个属性Ci 来计算信息增益。将当前节点 father 按照属于属性 Ci不同取值 划分为Ni个子集:
- fatherj:样本C属性为nj j∈1,2...Ni
其中,∣fatherj∣ 是 C的属性值为nj样本数
-
条件熵计算:
根据类别 Ci 的划分计算条件熵 H(father∣Ci),即按属性 Ci 划分后的加权熵:
H(father∣Ci)=j=1∑Ni∣father∣∣fatherj∣H(fatherj)
-
信息增益:
类别 Ci 的信息增益 IG(Ci) 计算为:
IG(Ci)=H(father)−H(father∣Ci)
-
选取信息增益最大的类别:
计算所有类别 C1,C2,…,Ck 的信息增益,选择信息增益最大的类别 Cbest 作为当前节点的判别类别:
Cbest=argimaxIG(Ci)
-
继续递归:
根据选中的判别类别 Cbest 将数据集划分为子集,并递归执行以上步骤,直到满足终止条件。
信息增益(information gain):
g(D,A)=H(D)−H(D∣A)
- 已知随机变量A的值的前提下,随机变量D信息熵的减少量
- H(D∣A)=∑i=1nP(ai)H(D∣A=ai) 也被称为条件熵
在该实例中即为H(proot)−wleftH(pleft)−wrightH(pright)
- 当一个离散属性有k种取值
- 方式一:建立k个分支
- 方式二:one-hot编码,转变为k个属性,每个属性取值0或1
处理连续变量
上述特征都是针对于属性是离散的,例如动物要么有卷毛,要么没卷毛。但如果是连续的属性比如动物的体重呢?
假设X是连续的变量,则可以考虑以X<=k作为判别节点的特征
- 选择不同的阈值k计算信息增益,选取其中k使得信息增益最大的作为结果
构建树
参数调整以防过拟合
回归树
即预测输出cat or not cat,而是具体的一个数值
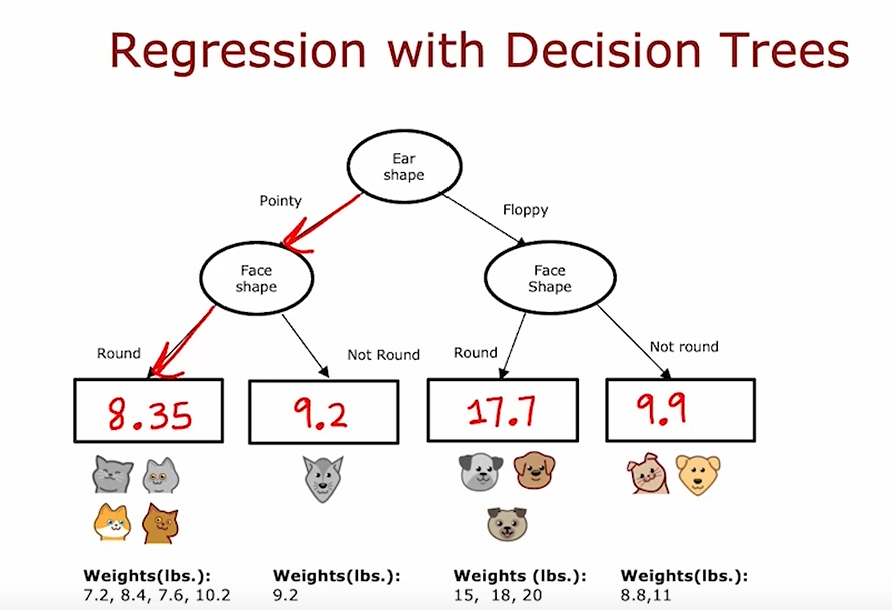
则输出即是叶节点中所有X 对应 y 的平均值