回顾DDPM
DDPM前提假设:
-
遵循马可夫链
前向固定:
q(x0:T)=q(x0)t=T∏1q(xt∣xt−1)
后向:
pθ(x0:T)=pθ(xT)t=T∏1pθ(xt−1∣xt)
-
定义加噪过程 : q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
-
损失函数:
L(θ)=−Ez∼q(x1:T∣x0)logq(x1:T∣x0)pθ(x0:T)=−Ez∼q(x1:T∣x0)logq(xT∣x0)∏t=2Tq(xt−1∣xt,x0)pθ(xT)⋅pθ(x0∣x1)∏t=2Tpθ(xt−1∣xt)
- 分母写成q(xT∣x0) 和q(xt−1∣xt,x0),为什么写成这种形式?
- 我们想反向的时候预测前向传播的噪声,但前向传播的噪声是q(xt∣xt−1),是后面依赖前面的形式,但反向时候是依赖反过来的,不能直接将q(xt∣xt−1)作为预测目标。所以我们要求出 q(xt−1∣xt,x0)关于噪声的表达式,然后让反向的时候预测。
- q(xT∣x0) 是前向传播已知, q(xt−1∣xt,x0)是我们想求出来的表达式,是反向的时候预测的目标
DDPM的具体推导详见xyfson学长的blog:DDPM,本文只是简要介绍背景和motivation
Motivation
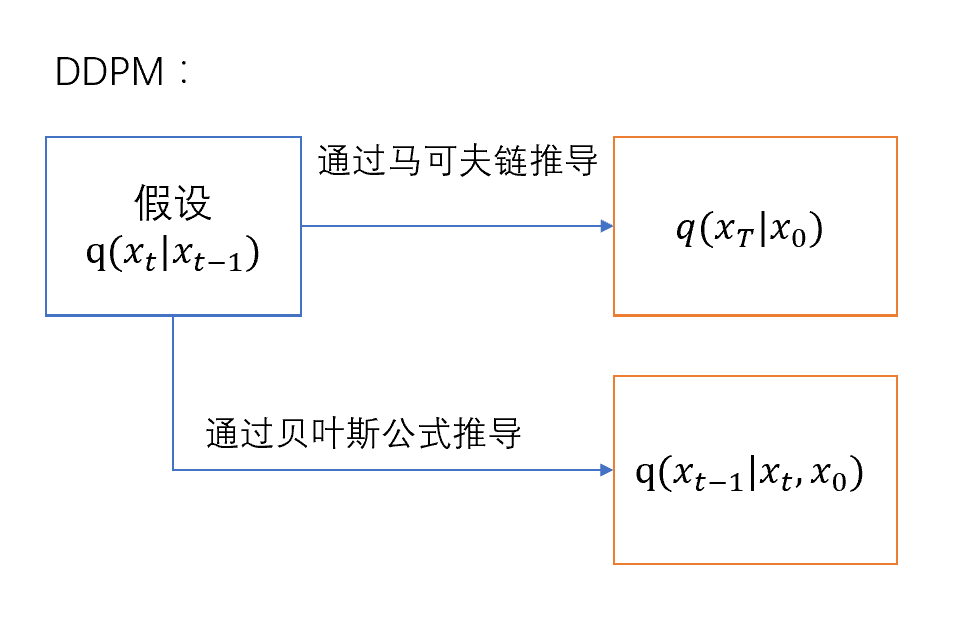
- 注意到DDPM由于马可夫链假设的限制,反向传播时不得不一步步预测,导致反向预测的时间步往往很长,速度很慢
- DDPM中的损失函数中并没有直接出现我们的假设q(xt∣xt−1)
大胆的想法:
能否绕过q(xt∣xt−1)和马可夫链,没必要一步步预测,直接定义q(xt−1∣xt,x0) 和q(xT∣x0) ?
DDIM
DDIM为了与DDPM对齐,定义:
q(xT∣x0)=N(xt;αˉx0,(1−αˉ)I)
通过约束q(xt−1∣x0)=∫q(xt−1∣xt,x0)q(xt∣x0)dx 求得q(xt−1∣xt,x0)的解,之后就和DDPM一样了。由于没有马可夫链的限制,反向可以只选择原DDPM时间步的一个子集进行训练和预测,大大提高速度。
具体推导见详见xyfson学长的blog:DDIM与加速采样