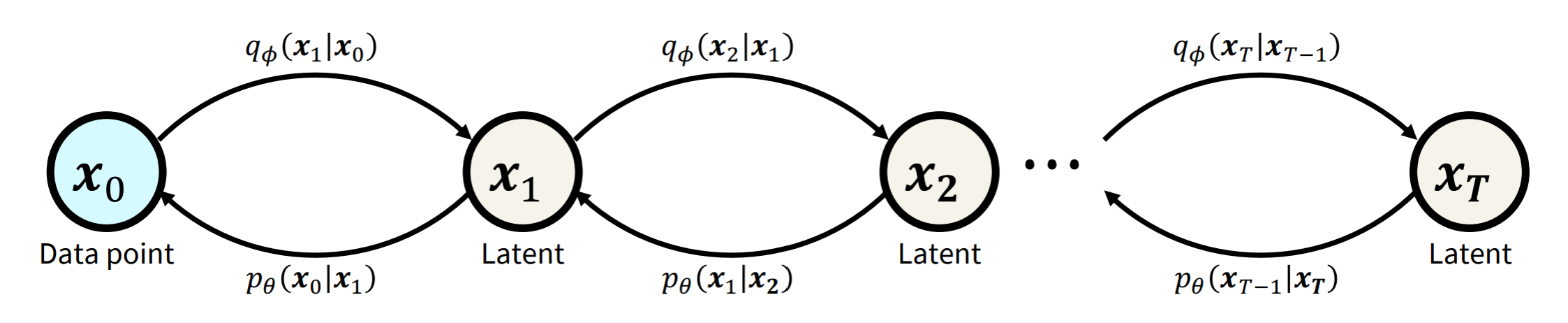
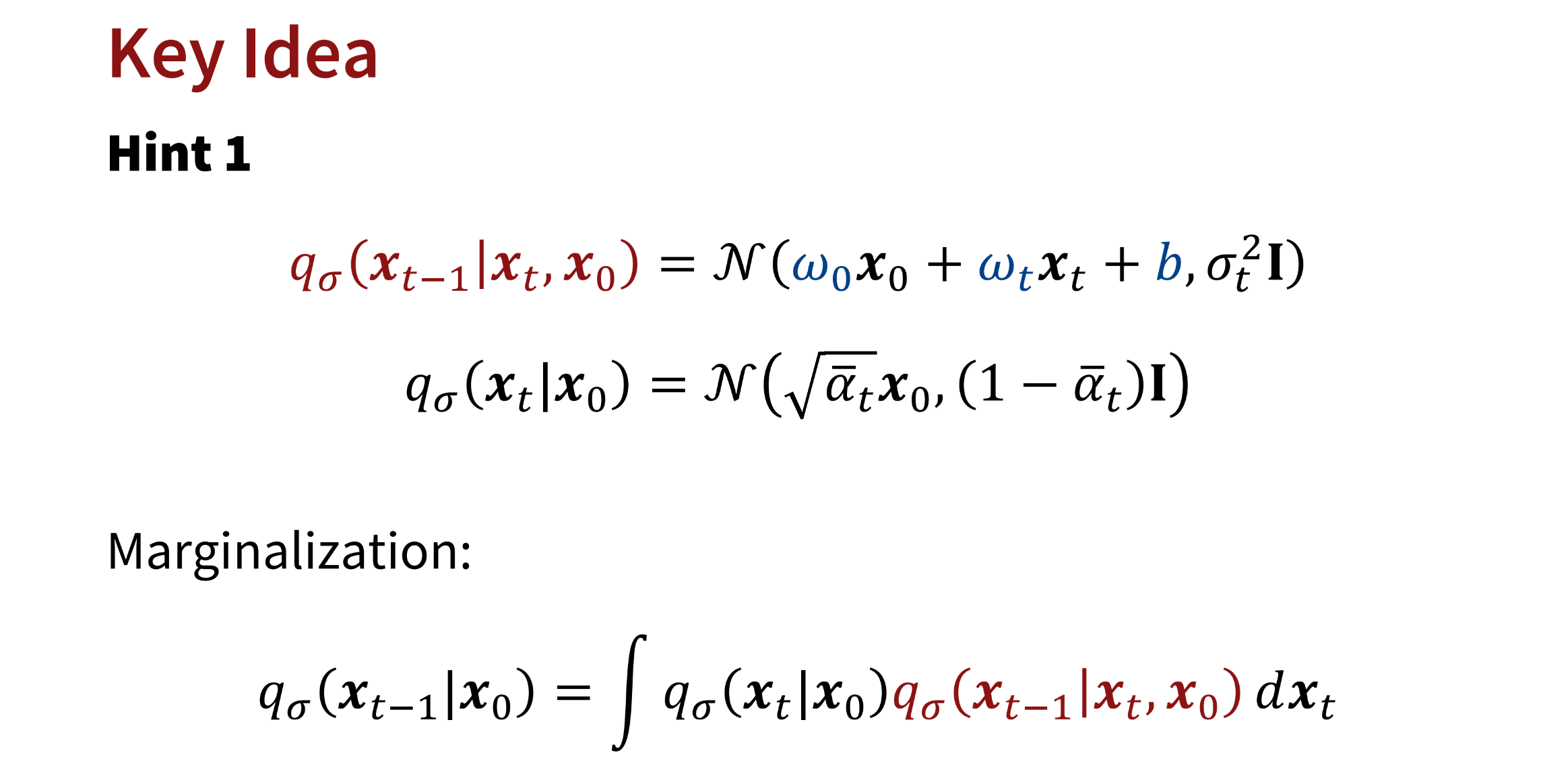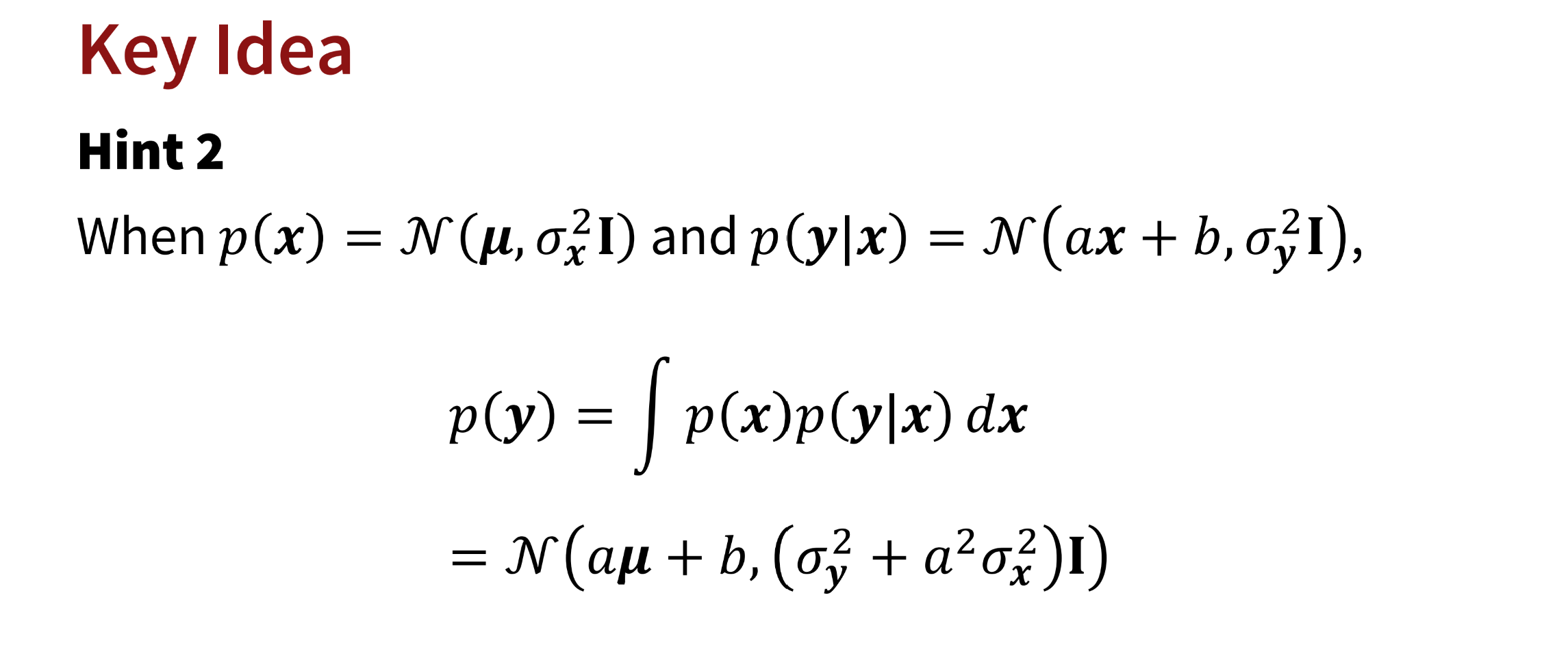DDPM
Brief Intro
从VAE的角度来看,VAE中只有一层隐变量,而DDPM将x 0 x_0 x 0 x 1 : T x_{1:T} x 1 : T
Assumptions
遵循马可夫链
前向predefined:
q ( x 0 : T ) = q ( x 0 ) ∏ t = T 1 q ( x t ∣ x t − 1 ) q(x_{0:T}) = q(x_0)\prod_{t=T}^{1} q(x_t|x_{t-1})
q ( x 0 : T ) = q ( x 0 ) t = T ∏ 1 q ( x t ∣ x t − 1 )
predefined 加噪过程 : q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t|x_{t-1}) = \mathcal N(x_t;\sqrt{1-\beta_t}x_{t-1}, \beta_t I) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I )
后向learn:
p θ ( x 0 : T ) = p θ ( x T ) ∏ t = T 1 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{0:T}) = p_{\theta}(x_T)\prod_{t=T}^{1} p_{\theta}(x_{t-1}|x_t)
p θ ( x 0 : T ) = p θ ( x T ) t = T ∏ 1 p θ ( x t − 1 ∣ x t )
DDPM定义前向传播 q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t|x_{t-1}) = \mathcal N(x_t;\sqrt{1-\beta_t}x_{t-1}, \beta_t I) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I )
故x t = 1 − β t x t − 1 + β t ϵ x_t = \sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t}\epsilon x t = 1 − β t x t − 1 + β t ϵ
令α t = 1 − β t \alpha_t = 1 - \beta_t α t = 1 − β t
则x t = α t x t − 1 + ( 1 − α t ) ϵ x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{(1-\alpha_t)}\epsilon x t = α t x t − 1 + ( 1 − α t ) ϵ
x t − 1 = α t − 2 x t − 2 + 1 − α t − 1 ϵ x_{t-1} = \sqrt{\alpha_{t-2}}x_{t-2} + \sqrt{1-\alpha_{t-1}}\epsilon x t − 1 = α t − 2 x t − 2 + 1 − α t − 1 ϵ
由于正态分布性质不难推出x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon x t = α ˉ t x 0 + 1 − α ˉ t ϵ
q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I ) q(x_t|x_0) = \mathcal N(x_0, \sqrt{\bar{\alpha}_t}x_0, {1-\bar\alpha_{t}}I) q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I )
Loss Function
其ELBO推导:
log p ( x 0 ) = log ∫ p θ ( x 0 : T ) d x 1 : T = l o g ∫ p θ ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) q ϕ ( x 1 : T ∣ x 0 ) d x 1 : T = l o g E q ϕ ( x 1 : T ∣ x 0 ) [ p θ ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) ] ≥ E q ϕ ( x 1 : T ∣ x 0 ) l o g [ p θ ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) ] \begin{align*}
\log p({x}_0) &= \log \int p_\theta({x}_{0:T}) d{x}_{1:T} \\
&= log \int p_\theta({x}_{0:T}) \frac{q_{\phi}(\mathbf{x}_{1:T}|x_0)}{q_{\phi}(\mathbf{x}_{1:T}|x_0)}dx_{1:T} \\
&= log\mathbb E_{q_{\phi}(x_{1:T}|x_0)}[ \frac{p_\theta({x}_{0:T})}{q_{\phi}(\mathbf{x}_{1:T}|x_0)}]\\
& \ge \mathbb E_{q_{\phi}(x_{1:T}|x_0)}log[ \frac{p_\theta({x}_{0:T})}{q_{\phi}(\mathbf{x}_{1:T}|x_0)}]
\end{align*}
log p ( x 0 ) = log ∫ p θ ( x 0 : T ) d x 1 : T = l o g ∫ p θ ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) q ϕ ( x 1 : T ∣ x 0 ) d x 1 : T = l o g E q ϕ ( x 1 : T ∣ x 0 ) [ q ϕ ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ≥ E q ϕ ( x 1 : T ∣ x 0 ) l o g [ q ϕ ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ]
最后一步的推导来自于Jensen 不等式
对于一个凹函数 f ( x ) f(x) f ( x )
f ( E [ X ] ) ≥ E [ f ( X ) ] f\left( \mathbb{E}[X] \right) \geq \mathbb{E}\left[ f(X) \right] f ( E [ X ] ) ≥ E [ f ( X ) ]
其中:
f ( x ) f(x) f ( x ) x x x 这次推导与上篇VAE形式略有不同,但本质相同,最后一步差的就是D K L ( q ϕ ( x 1 : T ∣ x 0 ) ∣ ∣ p ( x 1 : T ∣ x 0 ) ) D_{KL}(q_{\phi}(x_{1:T}|x_0)||p(x_{1:T}|x_0)) D K L ( q ϕ ( x 1 : T ∣ x 0 ) ∣∣ p ( x 1 : T ∣ x 0 ))
不妨换一种方式,以D K L ( q ϕ ( x 1 : T ∣ x 0 ) ∣ ∣ p ( x 1 : T ∣ x 0 ) ) \color{red}{D_{KL}(q_{\phi}(x_{1:T}|x_0)||p(x_{1:T}|x_0))} D K L ( q ϕ ( x 1 : T ∣ x 0 ) ∣∣ p ( x 1 : T ∣ x 0 ))
D K L ( q ϕ ( x 1 : T ∣ x 0 ) ∣ ∣ p ( x 1 : T ∣ x 0 ) ) = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 ) p ( x 1 : T ∣ x 0 ) ] = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 ) p ( x 0 : T ) p ( x 0 ) ] = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 ) p ( x 0 ) p ( x 0 : T ) ] = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 ) ] + E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 ) ] − E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 : T ) ] = l o g p ( x 0 ) + E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 ) ] − E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 : T ) ] = l o g p ( x 0 ) + E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 ) p ( x 0 : T ) ] \begin{aligned}{D_{KL}(q_{\phi}(x_{1:T}|x_0)||p(x_{1:T}|x_0))}&= \mathbb E_{q_{\phi}(x_{1:T}|x_0)}[log\frac{q_{\phi}(x_{1:T}|x_0)}{p(x_{1:T}|x_0)}] \\&= \mathbb E_{q_{\phi}(x_{1:T}|x_0)}[log\frac{q_{\phi}(x_{1:T}|x_0)}{\frac{p(x_{0:T})}{p(x_0)}}]\\&= \mathbb E_{q_{\phi}(x_{1:T}|x_0)}[log\frac{q_{\phi}(x_{1:T}|x_0)p(x_0)}{p(x_{0:T})}]\\&= E_{q_{\phi}(x_{1:T}|x_0)}[logp(x_0)] + E_{q_{\phi}(x_{1:T}|x_0)}[logq_{\phi}(x_{1:T}|x_0)] - E_{q_{\phi}(x_{1:T}|x_0)}[logp(x_{0:T})]\\&= logp(x_0) + E_{q_{\phi}(x_{1:T}|x_0)}[logq_{\phi}(x_{1:T}|x_0)] - E_{q_{\phi}(x_{1:T}|x_0)}[logp(x_{0:T})]\\&= logp(x_0) + E_{q_{\phi}(x_{1:T}|x_0)}[log\frac{q_{\phi}(x_{1:T}|x_0)}{p(x_{0:T})}] \end{aligned} D K L ( q ϕ ( x 1 : T ∣ x 0 ) ∣∣ p ( x 1 : T ∣ x 0 )) = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 1 : T ∣ x 0 ) q ϕ ( x 1 : T ∣ x 0 ) ] = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 ) p ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) ] = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) p ( x 0 ) ] = E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 )] + E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 )] − E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 : T )] = l o g p ( x 0 ) + E q ϕ ( x 1 : T ∣ x 0 ) [ l o g q ϕ ( x 1 : T ∣ x 0 )] − E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 : T )] = l o g p ( x 0 ) + E q ϕ ( x 1 : T ∣ x 0 ) [ l o g p ( x 0 : T ) q ϕ ( x 1 : T ∣ x 0 ) ]
损失函数:
L ( θ ) = − E z ∼ q ( x 1 : T ∣ x 0 ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) = − E z ∼ q ( x 1 : T ∣ x 0 ) log p θ ( x T ) ⋅ p θ ( x 0 ∣ x 1 ) ∏ t = 2 T p θ ( x t − 1 ∣ x t ) q ( x T ∣ x 0 ) ∏ t = 2 T q ( x t − 1 ∣ x t , x 0 ) = − E x 1 ∼ q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] ⏟ reconstruction + ∑ t = 2 T E x t ∼ q ( x t ∣ x t − 1 , x 0 ) [ D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ] ⏟ matching + D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) ⏟ regularization \begin{aligned}
\mathcal{L}(\theta) &= -\mathbb{E}_{z \sim q(x_{1:T} | x_0)} \log \frac{p_{\theta}(x_{0:T})}{q(x_{1:T} | x_0)} \\
&= -\mathbb{E}_{z \sim q(x_{1:T} | x_0)} \log \frac{p_{\theta}(x_T) \cdot p_{\theta}(x_0 | x_1) \prod_{t=2}^{T} p_{\theta}(x_{t-1} | x_t)}{q(x_T | x_0) \prod_{t=2}^{T} q(x_{t-1} | x_t, x_0)} \\
&= -\underbrace{\mathbb{E}_{x_1 \sim q(x_1|x_0)} \left[\log p_{\theta}(x_0 | x_1) \right]}_{\text{reconstruction}}
+ \underbrace{\sum_{t=2}^{T} \mathbb{E}_{x_t \sim q(x_t|x_{t-1}, x_0)} \left[ D_{\text{KL}}(q(x_{t-1} | x_t, x_0) \Vert p_{\theta}(x_{t-1} | x_t)) \right]}_{\text{matching}} + \underbrace{D_{\text{KL}}(q(x_T | x_0) \Vert p_{\theta}(x_T))}_{\text{regularization}}
\end{aligned}
L ( θ ) = − E z ∼ q ( x 1 : T ∣ x 0 ) log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) = − E z ∼ q ( x 1 : T ∣ x 0 ) log q ( x T ∣ x 0 ) ∏ t = 2 T q ( x t − 1 ∣ x t , x 0 ) p θ ( x T ) ⋅ p θ ( x 0 ∣ x 1 ) ∏ t = 2 T p θ ( x t − 1 ∣ x t ) = − reconstruction E x 1 ∼ q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] + matching t = 2 ∑ T E x t ∼ q ( x t ∣ x t − 1 , x 0 ) [ D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t )) ] + regularization D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ))
为什么在损失函数中将前向过程q q q q ( x T ∣ x 0 ) q(x_{T}|x_0) q ( x T ∣ x 0 ) q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q ( x t − 1 ∣ x t , x 0 )
因为损失函数作用是反向传播阶段,前向传播是q ( x t ∣ x t − 1 ) q(x_{t}|x_{t-1}) q ( x t ∣ x t − 1 ) q ( x t ∣ x t − 1 ) q(x_{t}|x_{t-1}) q ( x t ∣ x t − 1 )
因此我们要求出改写前向传播为时间序列由大到小的形式,这里最终推导出来是 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q ( x t − 1 ∣ x t , x 0 )
具体推导:
DDPM假设遵循马尔科夫链,因此q ( x t ∣ x t − 1 ) = q ( x t ∣ x t − 1 , x 0 ) q(x_t|x_{t-1}) = q(x_t|x_{t-1},x_0) q ( x t ∣ x t − 1 ) = q ( x t ∣ x t − 1 , x 0 )
又因为q ( x t , x t − 1 ∣ x 0 ) = q ( x t ∣ x t − 1 , x 0 ) ⋅ q ( x t − 1 ∣ x 0 ) . q({x}_{t}, {x}_{t-1} | {x}_0) = q({x}_{t} | {x}_{t-1}, {x}_0) \cdot q({x}_{t-1} | {x}_0). q ( x t , x t − 1 ∣ x 0 ) = q ( x t ∣ x t − 1 , x 0 ) ⋅ q ( x t − 1 ∣ x 0 ) .
q ( x 1 : T ∣ x 0 ) = q ( x 1 ∣ x 0 ) ∏ t = 2 T q ( x t ∣ x t − 1 ) = q ( x 1 ∣ x 0 ) ∏ t = 2 T q ( x t ∣ x t − 1 , x 0 ) = q ( x 1 ∣ x 0 ) ∏ t = 2 T q ( x t , x t − 1 ∣ x 0 ) q ( x t − 1 ∣ x 0 ) = q ( x 1 ∣ x 0 ) ∏ t = 2 T q ( x t ∣ x 0 ) q ( x t − 1 ∣ x t , x 0 ) q ( x t − 1 ∣ x 0 ) = q ( x T ∣ x 0 ) ∏ t = 2 T q ( x t − 1 ∣ x t , x 0 ) \begin{aligned}q(x_{1:T} | x_0) &= q(x_1|x_0)\prod_{t=2}^{T}q(x_t|x_{t-1}) \\&= q(x_1|x_0)\prod_{t=2}^{T}q(x_t|x_{t-1},x_0)\\&= q(x_1|x_0)\prod_{t=2}^{T}\frac{q({x}_{t}, {x}_{t-1} | {x}_0)}{q({x}_{t-1} | {x}_0)} \\&= q(x_1|x_0)\prod_{t=2}^{T}\frac{q({x}_{t}|x_0)q({x}_{t-1} |x_t, {x}_0)}{q({x}_{t-1} | {x}_0)} \\&= q(x_T|x_0)\prod_{t=2}^{T}q(x_{t-1}|x_t, x_0)\end{aligned} q ( x 1 : T ∣ x 0 ) = q ( x 1 ∣ x 0 ) t = 2 ∏ T q ( x t ∣ x t − 1 ) = q ( x 1 ∣ x 0 ) t = 2 ∏ T q ( x t ∣ x t − 1 , x 0 ) = q ( x 1 ∣ x 0 ) t = 2 ∏ T q ( x t − 1 ∣ x 0 ) q ( x t , x t − 1 ∣ x 0 ) = q ( x 1 ∣ x 0 ) t = 2 ∏ T q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x t , x 0 ) = q ( x T ∣ x 0 ) t = 2 ∏ T q ( x t − 1 ∣ x t , x 0 )
总结: q ( x T ∣ x 0 ) q(x_{T}|x_0) q ( x T ∣ x 0 ) q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q ( x t − 1 ∣ x t , x 0 ) 是反向的时候预测的目标
首先查看损失函数第三项prior loss
作者希望T − > ∞ T-> \infty T − > ∞ q ( x T ∣ x 0 ) = N ( x 0 ; α T ˉ x 0 , 1 − α T I ) q(x_T|x_0)= \mathcal N(x_0; \sqrt{\bar{\alpha_T}}x_0, {1-\alpha_{T}}I) q ( x T ∣ x 0 ) = N ( x 0 ; α T ˉ x 0 , 1 − α T I ) N ( x 0 ; 0 , I ) N(x_0;0,I) N ( x 0 ; 0 , I )
因此要求α t \alpha_t α t lim t → ∞ α t ˉ = 0 \lim_{t \to \infty} \bar{\alpha_t} = 0 lim t → ∞ α t ˉ = 0 β t \beta_t β t
由于q ( x T ∣ x 0 ) q(x_T|x_0) q ( x T ∣ x 0 ) p θ ( x T ) p_{\theta}(x_T) p θ ( x T )
再看第二项matching loss
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) D_{\text{KL}}(q(x_{t-1} | x_t, x_0) \Vert p_{\theta}(x_{t-1} | x_t))
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ))
q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , 1 − α t I ) q(x_t|x_{t-1}) = \mathcal N(x_t;\sqrt{\alpha_t}x_{t-1}, 1-\alpha_t I) q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , 1 − α t I )
q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I ) q(x_t|x_0) = \mathcal N(x_0, \sqrt{\bar{\alpha}_t}x_0, {1-\bar\alpha_{t}}I) q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I )
q ( x t − 1 ∣ x 0 ) = N ( x 0 , α ˉ t − 1 x 0 , 1 − α ˉ t − 1 I ) q(x_{t-1}|x_0) = \mathcal N(x_0, \sqrt{\bar{\alpha}_{t-1}}x_0, {1-\bar\alpha_{t-1}}I) q ( x t − 1 ∣ x 0 ) = N ( x 0 , α ˉ t − 1 x 0 , 1 − α ˉ t − 1 I )
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 1 − α t + ( x t − α ‾ t − 1 x 0 ) 2 1 − α ‾ t − 1 − ( x t − α ‾ t x 0 ) 2 1 − α ‾ t ) ) = ⋯ = N ( μ ~ ( x t , x 0 ) , σ ~ t 2 I ) Another normal distribution! \begin{align*}
q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)
&= q(\boldsymbol{x}_t|\boldsymbol{x}_{t-1}) \frac{q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_0)}{q(\boldsymbol{x}_t|\boldsymbol{x}_0)} \\
&\propto \exp\Biggl( -\frac{1}{2} \biggl(
\frac{(\boldsymbol{x}_t - \sqrt{\alpha_t}\boldsymbol{x}_{t-1})^2}{1 - \alpha_t}
+ \frac{(\boldsymbol{x}_t - \sqrt{\overline{\alpha}_{t-1}}\boldsymbol{x}_0)^2}{1 - \overline{\alpha}_{t-1}}
- \frac{(\boldsymbol{x}_t - \sqrt{\overline{\alpha}_t}\boldsymbol{x}_0)^2}{1 - \overline{\alpha}_t}
\biggr) \Biggr) \\
&= \ \cdots \\
&= \mathcal{N}\left( \widetilde{\mu}(\boldsymbol{x}_t, \boldsymbol{x}_0),\ \widetilde{\sigma}_t^2\mathbf{I} \right)
\quad \text{\color{blue}Another normal distribution!}
\end{align*}
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ∝ exp ( − 2 1 ( 1 − α t ( x t − α t x t − 1 ) 2 + 1 − α t − 1 ( x t − α t − 1 x 0 ) 2 − 1 − α t ( x t − α t x 0 ) 2 ) ) = ⋯ = N ( μ ( x t , x 0 ) , σ t 2 I ) Another normal distribution!
通过将上式展开,求解一元二次方程的根,我们得到u ( x t , x 0 ) u(x_t,x_0) u ( x t , x 0 ) σ ~ t \tilde \sigma_t σ ~ t
where μ ~ ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \tilde{\mu}(x_t, x_0) = \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1 - \bar{\alpha}_t} x_0 μ ~ ( x t , x 0 ) = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 β t x 0 σ ~ t 2 = 1 − α ˉ t − 1 1 − α ˉ t β t \tilde{\sigma}_t^2 = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t σ ~ t 2 = 1 − α ˉ t 1 − α ˉ t − 1 β t
将x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon x t = α ˉ t x 0 + 1 − α ˉ t ϵ
u ~ ( x t , x 0 ) = 1 α ˉ t ( x t − 1 − α t 1 − α ˉ t ϵ ) \tilde u(x_t, x_0) = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \frac{1- \alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon) u ~ ( x t , x 0 ) = α ˉ t 1 ( x t − 1 − α ˉ t 1 − α t ϵ )
由于前向传播q ( x t − 1 ∣ x t , x 0 ) = N ( μ ~ ( x t , x 0 ) , σ ~ t 2 I ) q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0) = \mathcal{N}\left( \widetilde{\mu}(\boldsymbol{x}_t, \boldsymbol{x}_0),\ \widetilde{\sigma}_t^2\mathbf{I} \right) q ( x t − 1 ∣ x t , x 0 ) = N ( μ ( x t , x 0 ) , σ t 2 I )
因此DDPM中在后向传播作者定义相同的形式p θ ( x t − 1 ∣ x t ) = N ( μ θ ( x t , t ) , σ t 2 I ) p_{\theta}(x_{t-1} | x_t) = \mathcal{N}\left( {\mu_{\theta}}(\boldsymbol{x}_t, \boldsymbol{t}),\ {\sigma}_t^2\mathbf{I} \right) p θ ( x t − 1 ∣ x t ) = N ( μ θ ( x t , t ) , σ t 2 I )
特别地,这里σ t {\sigma}_t σ t σ t 2 = σ ~ t 2 = 1 − α ˉ t − 1 1 − α ˉ t β t \sigma_t^2 = \tilde{\sigma}_t^2 = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t σ t 2 = σ ~ t 2 = 1 − α ˉ t 1 − α ˉ t − 1 β t
mean-predictor
两个方差相同的正态分布做KL散度,根据公式则为
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) = 1 2 σ t 2 ∣ ∣ μ ~ ( x t , x 0 ) − μ θ ( x t , t ) ∣ ∣ 2 2 D_{\text{KL}}(q(x_{t-1} | x_t, x_0) \Vert p_{\theta}(x_{t-1} | x_t)) = \frac{1}{2\sigma_t^2}||\tilde{\mu}(x_t, x_0) - {\mu_{\theta}}(x_t, t) ||_2^2
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t )) = 2 σ t 2 1 ∣∣ μ ~ ( x t , x 0 ) − μ θ ( x t , t ) ∣ ∣ 2 2
x 0 x_0 x 0
μ ~ ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \tilde{\mu}(x_t, x_0) = \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1 - \bar{\alpha}_t} x_0 μ ~ ( x t , x 0 ) = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 β t x 0
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) = α ˉ t β t 2 2 σ t 2 ( 1 − α ˉ t ) 2 ∣ ∣ x 0 − x θ ( x t , t ) ∣ ∣ 2 2 D_{\text{KL}}(q(x_{t-1} | x_t, x_0) \Vert p_{\theta}(x_{t-1} | x_t)) = \frac{\bar{\alpha}_t\beta_t^2}{2\sigma_t^2(1 - \bar{\alpha}_t)^2}||x_0- x_{\theta}(x_t, t) ||_2^2
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t )) = 2 σ t 2 ( 1 − α ˉ t ) 2 α ˉ t β t 2 ∣∣ x 0 − x θ ( x t , t ) ∣ ∣ 2 2
ϵ \epsilon ϵ
u ~ ( x t , x 0 ) = 1 α ˉ t ( x t − 1 − α t 1 − α ˉ t ϵ ) \tilde u(x_t, x_0) = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \frac{1- \alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon) u ~ ( x t , x 0 ) = α ˉ t 1 ( x t − 1 − α ˉ t 1 − α t ϵ )
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) = ( 1 − α t ) 2 2 σ t 2 α ˉ t ( 1 − α ˉ t ) ∣ ∣ ϵ t − ϵ θ ( x t , t ) ∣ ∣ 2 2 D_{\text{KL}}(q(x_{t-1} | x_t, x_0) \Vert p_{\theta}(x_{t-1} | x_t)) = \frac{(1-\alpha_t)^2}{2\sigma_t^2{\bar{\alpha}}_t(1-\bar{\alpha}_t)}||\epsilon_t- \epsilon_{\theta}(x_t, t) ||_2^2
D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t )) = 2 σ t 2 α ˉ t ( 1 − α ˉ t ) ( 1 − α t ) 2 ∣∣ ϵ t − ϵ θ ( x t , t ) ∣ ∣ 2 2
最后第一项reconstruction loss
即重构损失,本质上和第二项损失相同,可以合并
最终的损失函数
E x 0 ∼ q ( x 0 ) , t > 1 , q ( x t ∣ x 0 ) [ ∣ ∣ ϵ t − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] \mathbb{E}_{x_0\sim q(x_0) ,t>1, q(x_t|x_0)}[||\epsilon_t - \epsilon_{\theta}(x_t,t)||_2^2]
E x 0 ∼ q ( x 0 ) , t > 1 , q ( x t ∣ x 0 ) [ ∣∣ ϵ t − ϵ θ ( x t , t ) ∣ ∣ 2 2 ]
而当t=1时,通常不固定,部分方法采取直接预测x 0 x_0 x 0
Traning
Generation
采样方法实际上为Langevin Dynamics Sampling , 还额外增加一个随机力z z z
Experiment Result
在AFHQ 数据集的cat类别 32x32 图像分辨率下,训练150,000个steps后,采样2k张图片FID约为45左右
采样结果如下:
DDIM
Motivation
注意到DDPM由于马可夫链假设的限制,反向传播时不得不一步步预测,导致反向预测的时间步往往很长,速度很慢
DDPM中的损失函数中并没有直接出现我们的假设q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q ( x t ∣ x t − 1 ) q ( x t , x t − 1 ∣ x 0 ) q({x}_{t}, {x}_{t-1} | {x}_0) q ( x t , x t − 1 ∣ x 0 )
大胆的想法:
能否绕过q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q ( x t − 1 ∣ x t , x 0 )
有读者可能会问,DDPM的损失函数不是用到了马尔科夫链的性质吗,事实上DDIM并不是直接拿DDPM的损失公式来用,而是假设
q σ ( x 1 : T ∣ x 0 ) = q σ ( x T ∣ x 0 ) ∏ t = 2 T q σ ( x t − 1 ∣ x t , x 0 ) q_\sigma(x_{1:T} | x_0) = q_\sigma(x_T | x_0) \prod_{t=2}^T q_\sigma(x_{t-1} | x_t, x_0)
q σ ( x 1 : T ∣ x 0 ) = q σ ( x T ∣ x 0 ) t = 2 ∏ T q σ ( x t − 1 ∣ x t , x 0 )
进一步证明了DDIM和DDPM损失函数之差是一个常数
Method
DDIM中作者定义
q σ ( x t ∣ x t − 1 , x 0 ) = N ( w 0 x 0 + w t x t + b , σ t 2 I ) q_{\sigma}(x_t|x_{t-1},x_0) = \mathcal N(w_0 x_0 + w_tx_t + b, \sigma_t^2I) q σ ( x t ∣ x t − 1 , x 0 ) = N ( w 0 x 0 + w t x t + b , σ t 2 I )
如何确定系数w 0 w_0 w 0 w t w_t w t b b b
作者希望从 q σ ( x t ∣ x t − 1 , x 0 ) q_{\sigma}(x_t|x_{t-1},x_0) q σ ( x t ∣ x t − 1 , x 0 ) q σ ( x t ∣ x 0 ) q_{\sigma}(x_t|x_0) q σ ( x t ∣ x 0 ) q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I ) q(x_t|x_0) = \mathcal N(x_0, \sqrt{\bar{\alpha}_t}x_0, {1-\bar\alpha_{t}}I) q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I )
考虑更简单的情形,已知
q σ ( x t ∣ x t − 1 , x 0 ) = N ( w 0 x 0 + w t x t + b , σ t 2 I ) q_{\sigma}(x_t|x_{t-1},x_0) = \mathcal N(w_0 x_0 + w_tx_t + b, \sigma_t^2I) q σ ( x t ∣ x t − 1 , x 0 ) = N ( w 0 x 0 + w t x t + b , σ t 2 I ) q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I ) q(x_t|x_0) = \mathcal N(x_0, \sqrt{\bar{\alpha}_t}x_0, {1-\bar\alpha_{t}}I) q ( x t ∣ x 0 ) = N ( x 0 , α ˉ t x 0 , 1 − α ˉ t I )
如何保证q ( x t − 1 ∣ x 0 ) = N ( x 0 , α ˉ t − 1 x 0 , 1 − α ˉ t − 1 I ) q(x_{t-1}|x_0) = \mathcal N(x_0, \sqrt{\bar{\alpha}_{t-1}}x_0, {1-\bar\alpha_{t-1}}I) q ( x t − 1 ∣ x 0 ) = N ( x 0 , α ˉ t − 1 x 0 , 1 − α ˉ t − 1 I )
由此推导得到
q ( x t − 1 ∣ x 0 ) = N ( x 0 , α ˉ t − 1 x 0 , 1 − α ˉ t − 1 I ) = N ( x 0 , w 0 x 0 + w t α ˉ t x 0 + b , ( σ t 2 + w t 2 ( 1 − α ˉ t ) ) I ) \begin{align*}
q(x_{t-1}|x_0) &= \mathcal N(x_0, \sqrt{\bar{\alpha}_{t-1}}x_0, {1-\bar\alpha_{t-1}}I)\\
&= \mathcal N(x_0, w_0x_0 + w_t\sqrt{\bar{\alpha}_t}x_0 + b, (\sigma_t^2+w_{t}^2({1-\bar\alpha_{t}}))I)
\end{align*}
q ( x t − 1 ∣ x 0 ) = N ( x 0 , α ˉ t − 1 x 0 , 1 − α ˉ t − 1 I ) = N ( x 0 , w 0 x 0 + w t α ˉ t x 0 + b , ( σ t 2 + w t 2 ( 1 − α ˉ t )) I )
不妨令 b b b
w t = 1 − α ˉ t − 1 − σ t 2 ( 1 − α ˉ t ) w_t = \sqrt{\frac{1- \bar{\alpha}_{t-1} - \sigma_t^2}{(1-\bar{\alpha}_t)}} w t = ( 1 − α ˉ t ) 1 − α ˉ t − 1 − σ t 2
w 0 = α ˉ t − 1 − α ˉ t 1 − α ˉ t − 1 − σ t 2 ( 1 − α ˉ t ) w_0 = \sqrt{\bar{\alpha}_{t-1}} - \sqrt{\bar{\alpha}_{t}}\sqrt{\frac{1- \bar{\alpha}_{t-1} - \sigma_t^2}{(1-\bar{\alpha}_t)}} w 0 = α ˉ t − 1 − α ˉ t ( 1 − α ˉ t ) 1 − α ˉ t − 1 − σ t 2
带入q σ ( x t ∣ x t − 1 , x 0 ) = N ( w 0 x 0 + w t x t + b , σ t 2 I ) q_{\sigma}(x_t|x_{t-1},x_0) = \mathcal N(w_0 x_0 + w_tx_t + b, \sigma_t^2I) q σ ( x t ∣ x t − 1 , x 0 ) = N ( w 0 x 0 + w t x t + b , σ t 2 I )
最终得到
令σ t = η σ ~ t = η 1 − α ˉ t − 1 1 − α ˉ t β t \sigma_t = \eta \tilde{\sigma}_t = \eta \sqrt{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t} σ t = η σ ~ t = η 1 − α ˉ t 1 − α ˉ t − 1 β t
η \eta η η \eta η 反向扩散 都变为确定性过程
注意,从始至终本文DDIM中并没有讨论前向传播的过程,因为理论上DDIM是作为在采样时的一种策略,通常仍然使用DDPM训练。
事实上,当方差为0时,其对应的隐式前向传播不再是随机采样 ,而是通过反向过程的逆运算 计算得到,涉及到ODE, 具体可见DDIM Inversion
其反向扩散过程的确定性是指,一旦给出采样出x T x_T x T x 0 x_0 x 0 z z z
Faster Sampling
相较于训练时采取的总时间步T T T T T T [ t s 1 , t s 2 . . . t s k ] [t_{s1}, t_{s2} ...t_{sk}] [ t s 1 , t s 2 ... t s k ]
CFG
上述方法中都是无条件扩散模型,其生成的图像是随机的。但实际上我们肯定希望能生成想要的图片。因此引入Classifier-free-guidance
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t , y ) − ∇ x t log p ( y ) = ∇ x t log p ( x t ) + ∇ x t log p ( y ∣ x t ) − ∇ x t log p ( y ) = ∇ x t log p ( x t ) + ∇ x t log p ( y ∣ x t ) \begin{align}
\nabla_{x_t}\log p(x_t|y) &= \nabla_{x_t}\log p(x_t,y) - \nabla_{x_t}\log p(y) \\
&=\nabla_{x_t}\log p(x_t) + \nabla_{x_t}\log p(y|x_t) -\nabla_{x_t} \log p(y) \\
&= \nabla_{x_t}\log p(x_t) + \nabla_{x_t}\log p(y|x_t)
\end{align}
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t , y ) − ∇ x t log p ( y ) = ∇ x t log p ( x t ) + ∇ x t log p ( y ∣ x t ) − ∇ x t log p ( y ) = ∇ x t log p ( x t ) + ∇ x t log p ( y ∣ x t )
因此这便是 Classifier Guidance , 训练一个分类器,利用分类器的梯度来引导扩散模型生成。实际实践通常在前面加一个系数w , 用于控制引导幅度
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t ) + w ∇ x t log p ( y ∣ x t ) \begin{align}
\nabla_{x_t}\log p(x_t|y) &= \nabla_{x_t}\log p(x_t) + w\nabla_{x_t}\log p(y|x_t)
\end{align}
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t ) + w ∇ x t log p ( y ∣ x t )
然而该方法需要额外训练一个分类器,Classifier-Free Guidance 通过一个隐式的分类器来代替,
∇ x t log p ( y ∣ x t ) = ∇ x t log p ( x t , y ) − ∇ x t log p ( x ) \begin{align}
\nabla_{x_t}\log p(y|x_t) &= \nabla_{x_t}\log p(x_t,y) -\nabla_{x_t}\log p(x) \\
\end{align}
∇ x t log p ( y ∣ x t ) = ∇ x t log p ( x t , y ) − ∇ x t log p ( x )
带入上式可得
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t ) + w ( ∇ x t log p ( x t , y ) − ∇ x t log p ( x ) ) = ( 1 − w ) ∇ x t log p ( x t ) + w ∇ x t log p ( x t , y ) \begin{align}
\nabla_{x_t}\log p(x_t|y) &= \nabla_{x_t}\log p(x_t) + w(\nabla_{x_t}\log p(x_t,y) -\nabla_{x_t}\log p(x)) \\
&= (1-w)\nabla_{x_t}\log p(x_t) + w\nabla_{x_t}\log p(x_t,y)
\end{align}
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t ) + w ( ∇ x t log p ( x t , y ) − ∇ x t log p ( x )) = ( 1 − w ) ∇ x t log p ( x t ) + w ∇ x t log p ( x t , y )
因此
ϵ ^ θ ( x t , y ) = ( 1 − w ) ϵ θ ( x t ) ) + w ϵ θ ( x t , y ) ) \hat \epsilon_{\theta}(x_t, y) = (1-w)\epsilon_{\theta}(x_t)) + w\epsilon_{\theta}(x_t,y))
ϵ ^ θ ( x t , y ) = ( 1 − w ) ϵ θ ( x t )) + w ϵ θ ( x t , y ))
DDIM Inversion
当标准差为0时
x 0 ∣ t = 1 α ˉ t ( x t − 1 − α ˉ t ϵ θ ( x t , t ) ) x_{0|t} = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1 - \bar{\alpha}_t}\epsilon_{\theta}(x_t,t))
x 0∣ t = α ˉ t 1 ( x t − 1 − α ˉ t ϵ θ ( x t , t ))
x t − 1 = α ˉ t − 1 x 0 ∣ t + 1 − α ˉ t − 1 ϵ θ ( x t , t ) ) = α ˉ t − 1 [ 1 α ˉ t x t + ( 1 α ˉ t − 1 − 1 − 1 α ˉ t − 1 ) ϵ θ ( x t , t ) ] \begin{align}
x_{t-1} &= \sqrt{\bar{\alpha}_{t-1}}x_{0|t} + \sqrt{1 - \bar{\alpha}_{t-1}}\epsilon_{\theta}(x_t,t)) \\
&=\sqrt{\bar{\alpha}_{t-1}}[\frac{1}{\sqrt{\bar{\alpha}_{t}}}x_t + (\sqrt{\frac{1}{\bar{\alpha}_{t-1}}-1} - \sqrt{\frac{1}{\bar{\alpha}_{t}}-1}) \epsilon_{\theta}(x_t,t)]
\end{align}
x t − 1 = α ˉ t − 1 x 0∣ t + 1 − α ˉ t − 1 ϵ θ ( x t , t )) = α ˉ t − 1 [ α ˉ t 1 x t + ( α ˉ t − 1 1 − 1 − α ˉ t 1 − 1 ) ϵ θ ( x t , t )]
则
x t − 1 − x t = α ˉ t − 1 x 0 ∣ t + 1 − α ˉ t − 1 ϵ θ ( x t , t ) ) = α ˉ t − 1 [ ( 1 α ˉ t − 1 α ˉ t − 1 ) x t + ( 1 α ˉ t − 1 − 1 − 1 α ˉ t − 1 ) ϵ θ ( x t , t ) ] \begin{align}
x_{t-1} - x_t &= \sqrt{\bar{\alpha}_{t-1}}x_{0|t} + \sqrt{1 - \bar{\alpha}_{t-1}}\epsilon_{\theta}(x_t,t)) \\
&=\sqrt{\bar{\alpha}_{t-1}}[(\frac{1}{\sqrt{\bar{\alpha}_{t}}} - \frac{1}{\sqrt{\bar{\alpha}_{t-1}}})x_t + (\sqrt{\frac{1}{\bar{\alpha}_{t-1}}-1} - \sqrt{\frac{1}{\bar{\alpha}_{t}}-1}) \epsilon_{\theta}(x_t,t)]
\end{align}
x t − 1 − x t = α ˉ t − 1 x 0∣ t + 1 − α ˉ t − 1 ϵ θ ( x t , t )) = α ˉ t − 1 [( α ˉ t 1 − α ˉ t − 1 1 ) x t + ( α ˉ t − 1 1 − 1 − α ˉ t 1 − 1 ) ϵ θ ( x t , t )]
我们已经得到x t 1 − x t 2 x_{t_1} - x_{t2} x t 1 − x t 2 Δ t \Delta t Δ t x t + 1 − x t x_{t+1} - x_t x t + 1 − x t
x t + 1 − x t = α ˉ t + 1 x 0 ∣ t + 1 − α ˉ t + 1 ϵ θ ( x t , t ) ) = α ˉ t + 1 [ ( 1 α ˉ t − 1 α ˉ t + 1 ) x t + ( 1 α ˉ t + 1 − 1 − 1 α ˉ t − 1 ) ϵ θ ( x t , t ) ] \begin{align}
x_{t+1} - x_t &= \sqrt{\bar{\alpha}_{t+1}}x_{0|t} + \sqrt{1 - \bar{\alpha}_{t+1}}\epsilon_{\theta}(x_t,t)) \\
&=\sqrt{\bar{\alpha}_{t+1}}[(\frac{1}{\sqrt{\bar{\alpha}_{t}}} - \frac{1}{\sqrt{\bar{\alpha}_{t+1}}})x_t + (\sqrt{\frac{1}{\bar{\alpha}_{t+1}}-1} - \sqrt{\frac{1}{\bar{\alpha}_{t}}-1}) \epsilon_{\theta}(x_t,t)]
\end{align}
x t + 1 − x t = α ˉ t + 1 x 0∣ t + 1 − α ˉ t + 1 ϵ θ ( x t , t )) = α ˉ t + 1 [( α ˉ t 1 − α ˉ t + 1 1 ) x t + ( α ˉ t + 1 1 − 1 − α ˉ t 1 − 1 ) ϵ θ ( x t , t )]
应用:
图像编辑:
CFG扩散模型对图像做DDIM inversion后得到z, 利用z经过新的文本,使用CFG扩散模型得到编辑后的图像。但当CFG使用的w过大时,存在失真现象,原因就在于权重w会导致错误累积。
Null-text: 先使用CFG w=1扩散模型对图像DDIM inversion后得到z z z z ∗ z^{*} z ∗ z z z z ∗ z^{*} z ∗
Score Matching
Score function
Energy-based model 定义了使用函数模拟概率密度函数PDF的基本形式
p ( x ) = e − f θ ( x ) Z θ p(x) = \frac{e^{-f_{\theta}(x)}}{Z_{\theta}}
p ( x ) = Z θ e − f θ ( x )
PDF中的两个约束
在x x x
在x x x
Z θ Z_{\theta} Z θ
然而实际情况由于x x x Z θ Z_{\theta} Z θ
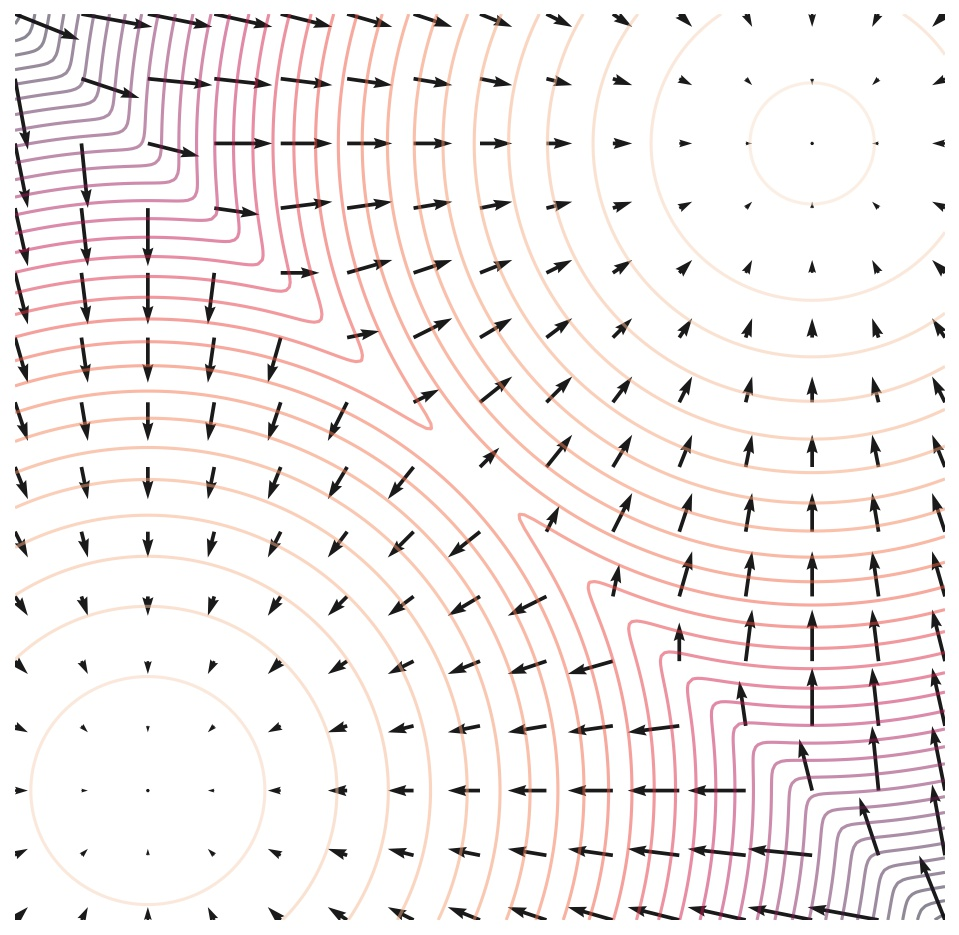
Score-based model
s θ ( x ) = ∇ x l o g p θ ( x ) = ∇ x l o g e − f ( x ) Z θ = − ∇ x f θ ( x ) s_{\theta}(x)=\nabla_{x}logp_{\theta}(x) = \nabla_{x}log\frac{e^{-f(x)}}{Z_{\theta}} = -\nabla_{x}f_{\theta}(x)
s θ ( x ) = ∇ x l o g p θ ( x ) = ∇ x l o g Z θ e − f ( x ) = − ∇ x f θ ( x )
很高兴地,令人讨厌的Z θ Z_{\theta} Z θ
由此,Score Matching是通过匹配原始PDF导数和模型学出来s θ ( x ) s_{\theta}(x) s θ ( x )
L ( θ ) = 1 2 E x ∼ p ( x ) ∣ ∣ ∇ x l o g p ( x ) − s θ ( x ) ∣ ∣ 2 2 \mathcal{L}(\theta) = \frac{1}{2}E_{x\sim p(x)}||\nabla_{x}logp(x) - s_{\theta}(x)||_2^2
L ( θ ) = 2 1 E x ∼ p ( x ) ∣∣ ∇ x l o g p ( x ) − s θ ( x ) ∣ ∣ 2 2
只要模型能够很好地拟合出函数的导数,那对这个导数求积分就是我们想得到的PDF
具体地,在空间中任意采样一点x 0 x_0 x 0 s θ ( x ) s_{\theta}(x) s θ ( x ) x 0 x_{0} x 0 x d a t a x_{data} x d a t a
然而,由于我们不知道真实的p ( x ) p(x) p ( x ) ∇ x l o g p ( x ) \nabla_{x}logp(x) ∇ x l o g p ( x )
接下来需要利用数学上的一些tricks来简化:
start:
L ( θ ) = 1 2 E x ∼ p ( x ) ∣ ∣ ∇ x l o g p ( x ) − s θ ( x ) ∣ ∣ 2 2 \mathcal{L}(\theta) = \frac{1}{2}E_{x\sim p(x)}||\nabla_{x}logp(x) - s_{\theta}(x)||_2^2
L ( θ ) = 2 1 E x ∼ p ( x ) ∣∣ ∇ x l o g p ( x ) − s θ ( x ) ∣ ∣ 2 2
goal:
L ( θ ) = 1 2 E p ( x ) [ s θ ( x ) 2 ] + E p ( x ) [ ∇ x s θ ( x ) ] \begin{align*}
\mathcal{L}(\theta)
&= \frac{1}{2}\mathbb{E}_{p(x)}[s_{\theta}(x)^2] + \mathbb{E}_{p(x)}[\nabla_{x}s_{\theta}(x)]
\end{align*}
L ( θ ) = 2 1 E p ( x ) [ s θ ( x ) 2 ] + E p ( x ) [ ∇ x s θ ( x )]
完整推导过程:
首先平方和展开为三项
L ( θ ) = 1 2 E x ∼ p ( x ) ∣ ∣ ∇ x l o g p ( x ) − s θ ( x ) ∣ 2 2 ∣ = 1 2 ∫ p ( x ) [ ( ∇ x l o g p ( x ) ) 2 + s θ ( x ) 2 − 2 ∇ x l o g p ( x ) s θ ( x ) ] d x = 1 2 ∫ p ( x ) ( ∇ x l o g p ( x ) ) 2 d x + 1 2 ∫ p ( x ) s θ ( x ) 2 d x − ∫ p ( x ) ∇ x l o g p ( x ) s θ ( x ) d x \begin{align*}\mathcal{L}(\theta) &= \frac{1}{2}E_{x\sim p(x)}||\nabla_{x}logp(x) - s_{\theta}(x)|_2^2| \\&= \frac{1}{2} \int p(x)[(\nabla_{x}logp(x))^2 + s_{\theta}(x)^2 - 2\nabla_{x}logp(x)s_{\theta}(x)]dx \\&= \frac{1}{2} \int p(x)(\nabla_{x}logp(x))^2dx + \frac{1}{2} \int p(x)s_{\theta}(x)^2 dx -\int p(x)\nabla_{x}logp(x)s_{\theta}(x)dx \\\end{align*} L ( θ ) = 2 1 E x ∼ p ( x ) ∣∣ ∇ x l o g p ( x ) − s θ ( x ) ∣ 2 2 ∣ = 2 1 ∫ p ( x ) [( ∇ x l o g p ( x ) ) 2 + s θ ( x ) 2 − 2 ∇ x l o g p ( x ) s θ ( x )] d x = 2 1 ∫ p ( x ) ( ∇ x l o g p ( x ) ) 2 d x + 2 1 ∫ p ( x ) s θ ( x ) 2 d x − ∫ p ( x ) ∇ x l o g p ( x ) s θ ( x ) d x
第一项由于和s θ ( x ) s_{\theta}(x) s θ ( x )
对于最后一项
∫ p ( x ) ∇ x l o g p ( x ) s θ ( x ) d x = ∫ ∇ x p ( x ) s θ ( x ) d x = p ( x ) s θ ( x ) ∣ − i n f i n f − ∫ p ( x ) ∇ x s θ ( x ) d x = 0 − ∫ p ( x ) ∇ x s θ ( x ) d x \begin{align}\int p(x)\nabla_{x}logp(x)s_{\theta}(x)dx &= \int\nabla_{x}p(x)s_{\theta}(x)dx \\&= p(x)s_{\theta}(x)|_{-inf}^{inf} - \int p(x)\nabla_{x}s_{\theta}(x)dx \\&= 0 - \int p(x)\nabla_{x}s_{\theta}(x)dx \quad \\\end{align} ∫ p ( x ) ∇ x l o g p ( x ) s θ ( x ) d x = ∫ ∇ x p ( x ) s θ ( x ) d x = p ( x ) s θ ( x ) ∣ − in f in f − ∫ p ( x ) ∇ x s θ ( x ) d x = 0 − ∫ p ( x ) ∇ x s θ ( x ) d x
(1):∇ x l o g p ( x ) \nabla_{x}logp(x) ∇ x l o g p ( x ) ∇ x p ( x ) p ( x ) \frac{\nabla_x p(x)}{p(x)} p ( x ) ∇ x p ( x ) (2): 分部积分 (3):p ( x ) p(x) p ( x ) 带入损失函数最终得到
L ( θ ) = 1 2 ∫ p ( x ) s θ ( x ) 2 d x + ∫ p ( x ) ∇ x s θ ( x ) d x = 1 2 E p ( x ) [ s θ ( x ) 2 ] + E p ( x ) [ ∇ x s θ ( x ) ] \begin{align*}\mathcal{L}(\theta) &= \frac{1}{2} \int p(x)s_{\theta}(x)^2 dx + \int p(x)\nabla_{x}s_{\theta}(x)dx \\&= \frac{1}{2}\mathbb{E}_{p(x)}[s_{\theta}(x)^2] + \mathbb{E}_{p(x)}[\nabla_{x}s_{\theta}(x)]\end{align*} L ( θ ) = 2 1 ∫ p ( x ) s θ ( x ) 2 d x + ∫ p ( x ) ∇ x s θ ( x ) d x = 2 1 E p ( x ) [ s θ ( x ) 2 ] + E p ( x ) [ ∇ x s θ ( x )]
Problems
Expensive Traning:注意损失函数第二项实际上为雅可比矩阵,计算量极大
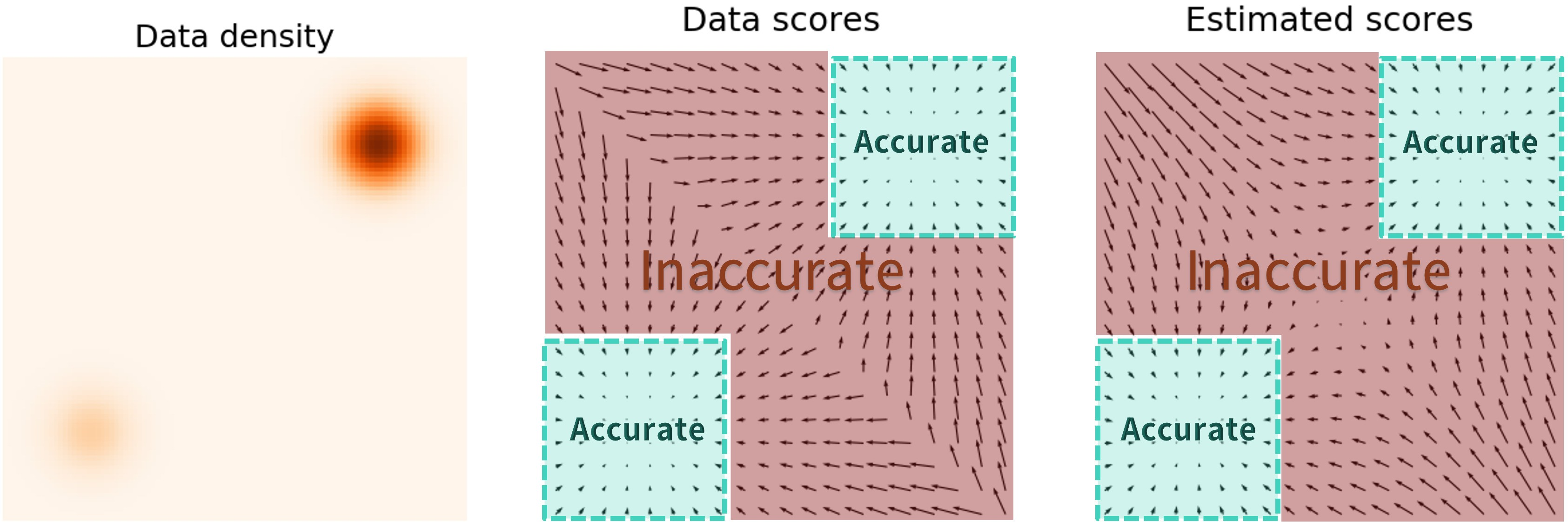
Low Converage of Data Space
Noise
数据空间覆盖得少,怎么办?先对数据加Noise!
x ~ = x + ϵ \tilde x = x + \epsilon x ~ = x + ϵ ϵ ∼ N ( 0 , σ 2 I ) \epsilon \sim N(0, \sigma^2 I) ϵ ∼ N ( 0 , σ 2 I )
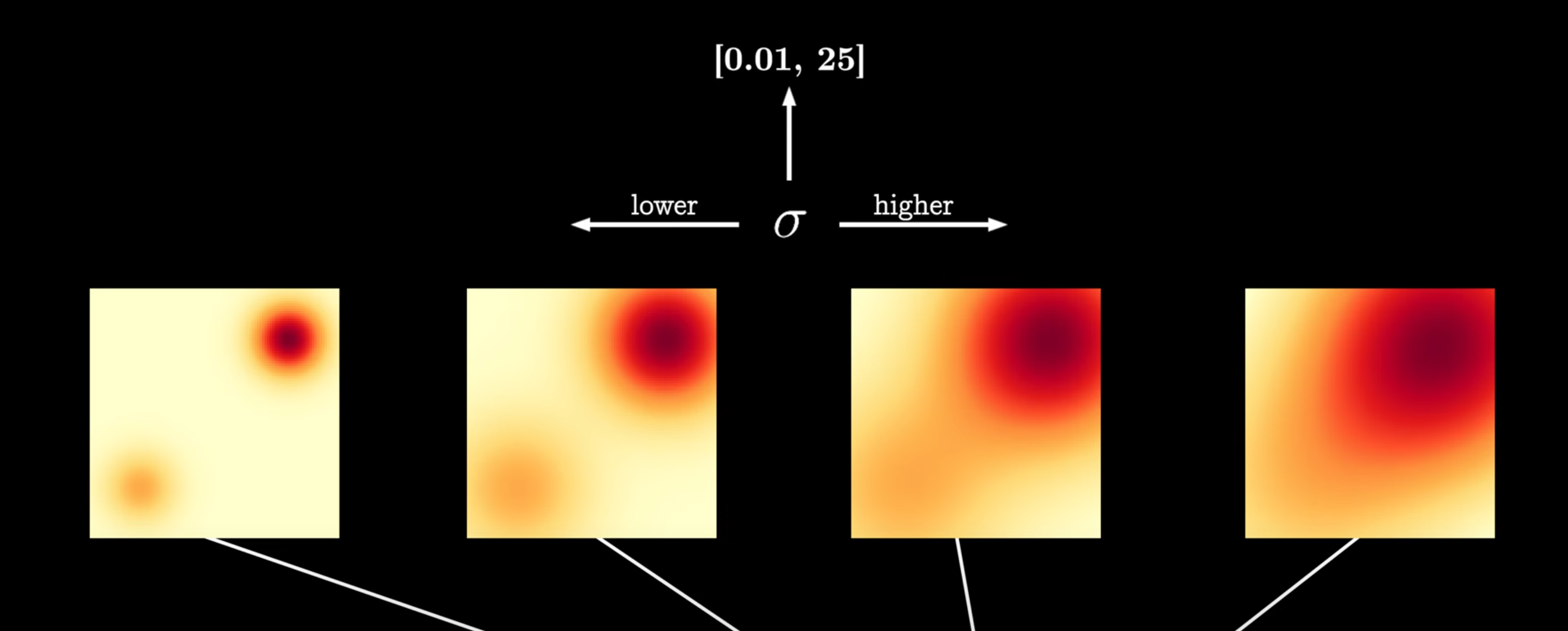
添加的扰动对应方差大训练见到的数据空间就多,方差小见到的数据就少
p ( x ) → p σ ( x ) p(x) \to p_{\sigma}(x) p ( x ) → p σ ( x )
这便得到了 Noise Conditional Score-based Model
但这只解决了Low Converage of Data Space的问题, 那Expensive Traning呢?
Denoising Score Matching
start:
L ( θ ) = 1 2 E x ~ ∼ p σ ( x ~ ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ) − s θ ( x ~ ) ∣ ∣ 2 2 \mathcal{L}(\theta) = \frac{1}{2}E_{\tilde x\sim p_{\sigma}(\tilde x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x) - s_{\theta}(\tilde x)||_2^2
L ( θ ) = 2 1 E x ~ ∼ p σ ( x ~ ) ∣∣ ∇ x ~ l o g p σ ( x ~ ) − s θ ( x ~ ) ∣ ∣ 2 2
goal:
L ( θ ) = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) − s θ ( x ~ ) ∣ ∣ 2 2 \mathcal{L}(\theta)
= \frac{1}{2}\mathbb{E}_{x\sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x|x) - s_{\theta}(\tilde x)||_2^2
L ( θ ) = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) − s θ ( x ~ ) ∣ ∣ 2 2
完整推导过程
平方项展开与之前相同
第三项化简:
∫ p σ ( x ~ ) ∇ x ~ l o g p ( x ~ ) s θ ( x ~ ) d x = ∫ ∇ x ~ p σ ( x ~ ) s θ ( x ~ ) d x ~ = ∫ ∇ x ~ ( ∫ p ( x ) p σ ( x ~ ∣ x ) d x ) s θ ( x ~ ) d x ~ = ∫ ( ∫ p ( x ) ∇ x ~ p σ ( x ~ ∣ x ) d x ) s θ ( x ~ ) d x ~ = ∫ ∫ p ( x ) p σ ( x ~ ∣ x ) ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) d x d x ~ \begin{align}\int p_{\sigma}(\tilde x)\nabla_{\tilde x}logp(\tilde x)s_{\theta}(\tilde x)dx &= \int\nabla_{\tilde x}p_{\sigma}(\tilde x)s_{\theta}(\tilde x)d\tilde x \\&= \int\nabla_{\tilde x}\textcolor{red}{(\int p(x)p_{\sigma}(\tilde x|x)dx)}s_{\theta}(\tilde x)d\tilde x \\&= \int\textcolor{red}{(\int p(x)\nabla_{\tilde x}p_{\sigma}(\tilde x|x)dx)}s_{\theta}(\tilde x)d\tilde x \\&= \int\int p(x)\textcolor{red}{p_{\sigma}(\tilde x|x)\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)}\textcolor{blue}{s_{\theta}(\tilde x)}dxd\tilde x \\\end{align} ∫ p σ ( x ~ ) ∇ x ~ l o g p ( x ~ ) s θ ( x ~ ) d x = ∫ ∇ x ~ p σ ( x ~ ) s θ ( x ~ ) d x ~ = ∫ ∇ x ~ ( ∫ p ( x ) p σ ( x ~ ∣ x ) d x ) s θ ( x ~ ) d x ~ = ∫ ( ∫ p ( x ) ∇ x ~ p σ ( x ~ ∣ x ) d x ) s θ ( x ~ ) d x ~ = ∫∫ p ( x ) p σ ( x ~ ∣ x ) ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) d x d x ~
(5): 利用边缘概率分布的定义 (6): 莱布尼兹积分规则 (7): ∇ x p ( x ) \nabla_x p(x) ∇ x p ( x ) p ( x ) ∇ x l o g p ( x ) p(x)\nabla_{x}logp(x) p ( x ) ∇ x l o g p ( x ) 带入损失函数变为
L ( θ ) = 1 2 E x ~ ∼ p σ ( x ~ ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ) ∣ ∣ 2 2 + 1 2 E x ~ ∼ p σ ( x ~ ) ∣ ∣ s θ ( x ~ ) ∣ ∣ 2 2 − E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣ ∣ \begin{align}\mathcal{L}(\theta)&= \frac{1}{2} \mathbb{E}_{\tilde x\sim p_{\sigma}(\tilde x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x)||_2^2 + \frac{1}{2} \mathbb{E}_{\tilde x\sim p_{\sigma}(\tilde x)}||s_{\theta}(\tilde x)||_2^2 - \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)s_{\theta}(\tilde x)||\\\end{align} L ( θ ) = 2 1 E x ~ ∼ p σ ( x ~ ) ∣∣ ∇ x ~ l o g p σ ( x ~ ) ∣ ∣ 2 2 + 2 1 E x ~ ∼ p σ ( x ~ ) ∣∣ s θ ( x ~ ) ∣ ∣ 2 2 − E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣∣
让我们关注后面两项
1 2 E x ~ ∼ p σ ( x ~ ) ∣ ∣ s θ ( x ~ ) ∣ ∣ 2 2 − E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣ ∣ 2 2 = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ s θ ( x ~ ) ∣ ∣ 2 2 − E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣ ∣ 2 2 = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∣ ∣ s θ ( x ~ ) 2 − 2 ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣ ∣ ] = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∣ ∣ s θ ( x ~ ) 2 − 2 ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) + ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 − ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 ∣ ∣ ] = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ s θ ( x ~ ) − ∇ x ~ l o g p σ ( x ~ ∣ x ) ∣ ∣ 2 2 − 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 ] \begin{align*}&\frac{1}{2} \mathbb{E}_{\tilde x\sim p_{\sigma}(\tilde x)}||s_{\theta}(\tilde x)||_2^2 - \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)s_{\theta}(\tilde x)||_2^2 \\&= \frac{1}{2} \mathbb{E}_{\textcolor{red}{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}}||s_{\theta}(\tilde x)||_2^2 - \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)s_{\theta}(\tilde x)||_2^2 \\&= \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}[||s_{\theta}(\tilde x)^2 - 2\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)s_{\theta}(\tilde x)||] \\&= \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}[||s_{\theta}(\tilde x)^2 - 2\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)s_{\theta}(\tilde x) + \textcolor{red}{\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)^2 - \nabla_{\tilde x}logp_{\sigma}(\tilde x|x)^2}||] \\&= \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||\textcolor{red}{s_{\theta}(\tilde x) -\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)}||_2^2 - \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}[\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)^2]\end{align*} 2 1 E x ~ ∼ p σ ( x ~ ) ∣∣ s θ ( x ~ ) ∣ ∣ 2 2 − E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣ ∣ 2 2 = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ s θ ( x ~ ) ∣ ∣ 2 2 − E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣ ∣ 2 2 = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∣∣ s θ ( x ~ ) 2 − 2 ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) ∣∣ ] = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∣∣ s θ ( x ~ ) 2 − 2 ∇ x ~ l o g p σ ( x ~ ∣ x ) s θ ( x ~ ) + ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 − ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 ∣∣ ] = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ s θ ( x ~ ) − ∇ x ~ l o g p σ ( x ~ ∣ x ) ∣ ∣ 2 2 − 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 ]
再次带入损失函数
L ( θ ) = 1 2 E x ~ ∼ p σ ( x ~ ) ∣ ∣ ∇ x ~ l o g p σ ( x ~ ) ∣ ∣ 2 2 + 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ s θ ( x ~ ) − ∇ x ~ l o g p σ ( x ~ ∣ x ) ∣ ∣ 2 2 − 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 ] \begin{align*}\mathcal{L}(\theta)&= \frac{1}{2} \mathbb{E}_{\tilde x\sim p_{\sigma}(\tilde x)}||\nabla_{\tilde x}logp_{\sigma}(\tilde x)||_2^2 +\frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||{s_{\theta}(\tilde x) -\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)}||_2^2 - \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}[\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)^2] \\\end{align*} L ( θ ) = 2 1 E x ~ ∼ p σ ( x ~ ) ∣∣ ∇ x ~ l o g p σ ( x ~ ) ∣ ∣ 2 2 + 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ s θ ( x ~ ) − ∇ x ~ l o g p σ ( x ~ ∣ x ) ∣ ∣ 2 2 − 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) [ ∇ x ~ l o g p σ ( x ~ ∣ x ) 2 ]
省略与score model无关的首尾两项:
L ( θ ) = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ s θ ( x ~ ) − ∇ x ~ l o g p σ ( x ~ ∣ x ) ∣ ∣ 2 2 \begin{align*}\mathcal{L}(\theta)&= \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||{s_{\theta}(\tilde x) -\nabla_{\tilde x}logp_{\sigma}(\tilde x|x)}||_2^2 \\\end{align*} L ( θ ) = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ s θ ( x ~ ) − ∇ x ~ l o g p σ ( x ~ ∣ x ) ∣ ∣ 2 2
你可能会疑惑,那这样∇ x ~ l o g p σ ( x ~ ∣ x ) \nabla_{\tilde x}logp_{\sigma}(\tilde x|x) ∇ x ~ l o g p σ ( x ~ ∣ x )
但我们实际思考,x ~ = x + ϵ \tilde x = x + \epsilon x ~ = x + ϵ p σ ( x ~ ∣ x ) = 1 ( 2 π ) d / 2 σ 2 e − 1 / 2 σ 2 ∣ x ~ − x ∣ 2 p_{\sigma}(\tilde x|x) = \frac{1}{(2\pi)^{d/2}\sigma^2} e^{-1/2\sigma^2|\tilde x - x|^2} p σ ( x ~ ∣ x ) = ( 2 π ) d /2 σ 2 1 e − 1/2 σ 2 ∣ x ~ − x ∣ 2
∇ x ~ l o g p σ ( x ~ ∣ x ) = 1 σ 2 ( x − x ~ ) = − 1 σ 2 ϵ \nabla_{\tilde x}logp_{\sigma}(\tilde x|x) = \frac{1}{\sigma^2}(x-\tilde x) = -\frac{1}{\sigma^2}\epsilon ∇ x ~ l o g p σ ( x ~ ∣ x ) = σ 2 1 ( x − x ~ ) = − σ 2 1 ϵ
L ( θ ) = 1 2 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣ ∣ s θ ( x ~ ) + 1 σ 2 ϵ ∣ ∣ 2 2 \begin{align*}
\mathcal{L}(\theta)
&= \frac{1}{2} \mathbb{E}_{x \sim p(x), \tilde x \sim p_{\sigma}(\tilde x|x)}||{s_{\theta}(\tilde x) + \frac{1}{\sigma^2} \epsilon}||_2^2 \\
\end{align*}
L ( θ ) = 2 1 E x ∼ p ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∣∣ s θ ( x ~ ) + σ 2 1 ϵ ∣ ∣ 2 2
Sampling
ok,训练过程已经介绍完了。我们在inference时如何生成图像呢,答案就是采样。
随机在空间选取一data point, 使用score model预测方向,移动一小步,如此往复
Simple Sample :
x ~ t + 1 = x ~ t + α s θ ( x ~ t ) \tilde x_{t+1} = \tilde x_{t} + \alpha s_{\theta}(\tilde x_t)
x ~ t + 1 = x ~ t + α s θ ( x ~ t )
缺点:最终所有的data point都很可能收敛到数据平均值,而不是数据分布的真实样本
Langevin Dynamics Sampling
引入随机力,这种扰动有助于采样器探索目标分布的其他模态,而不仅仅是集中在数据均值上
x ~ t + 1 = x ~ t + α s θ ( x ~ t ) + 2 α ϵ t {\tilde x}_{t+1} = \tilde x_t + \alpha s_{\theta}(\tilde x_t)+ \sqrt{2\alpha} {\epsilon}_t
x ~ t + 1 = x ~ t + α s θ ( x ~ t ) + 2 α ϵ t
这里x ~ 0 = x + ϵ \tilde x_0 = x + \epsilon x ~ 0 = x + ϵ ϵ ∼ N ( 0 , σ 2 I ) \epsilon \sim N(0,\sigma^2I) ϵ ∼ N ( 0 , σ 2 I )
紧接着我们再思考,与像DenoiseAutoEncoder其对数据加完噪声之后在训练,为何不在训练过程中边加噪声边训练呢?
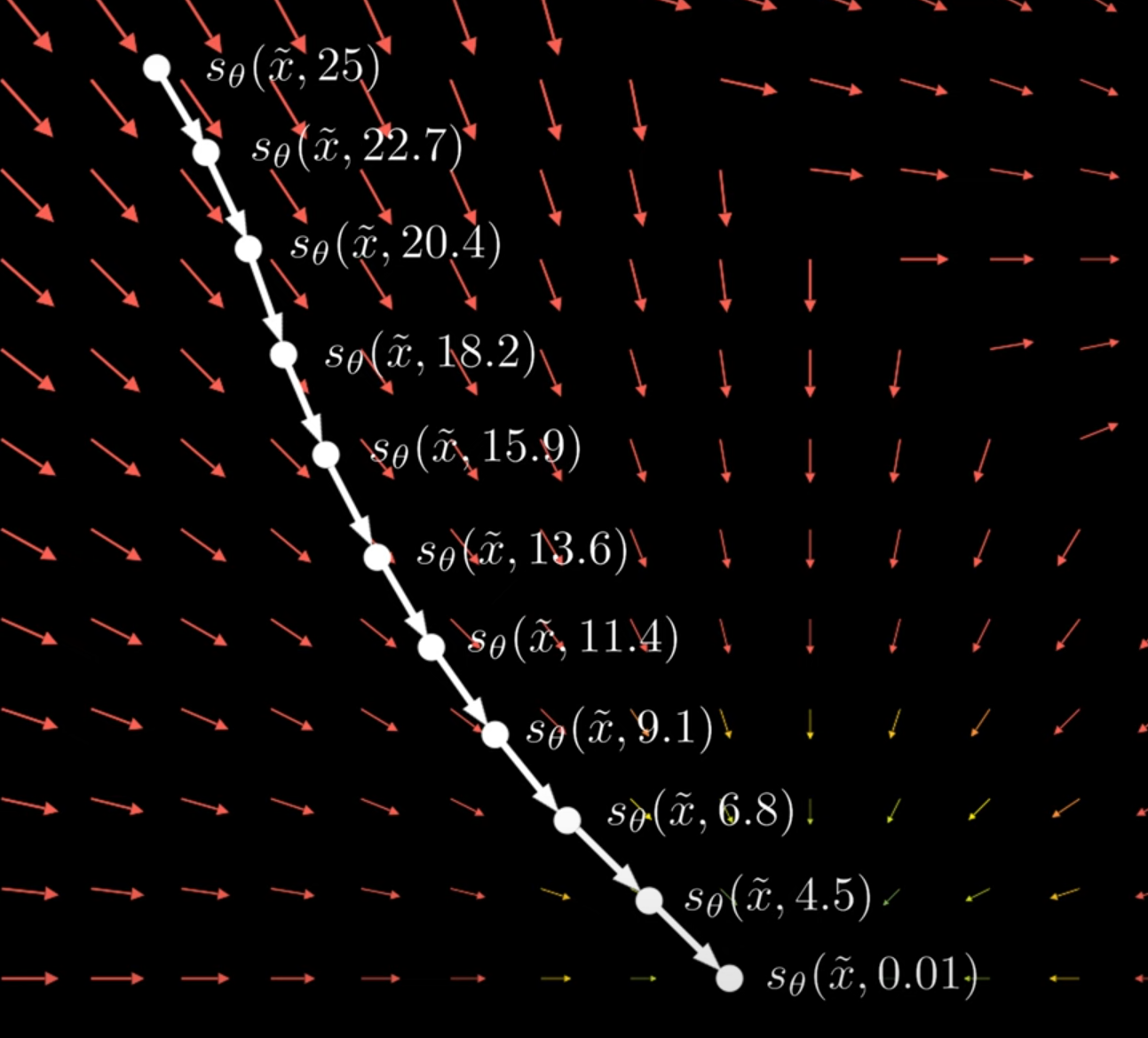
当噪声大时,模型能够见到更多的数据空间,增强鲁棒性/噪声小时,模型能够学到更精确的score
现在score model变为s θ ( x ~ , σ t ) s_{\theta}(\tilde x, \sigma_t) s θ ( x ~ , σ t )
Score-Based Generative Modeling through Stochastic Differential Equations 指出,当添加的噪声级别到大无穷多的时候,演变为随机过程。
SDE
随机过程描述随时间或空间变化的随机现象的一类系统,它可以通过随机微分方程来描述
d x = f ( x , t ) d t + g ( t ) d w dx = f(x,t)dt + g(t)dw
d x = f ( x , t ) d t + g ( t ) d w
f ( x , t ) f(x,t) f ( x , t ) g ( t ) g(t) g ( t ) w w w d w ∼ N ( 0 , d t ) dw∼N(0,dt) d w ∼ N ( 0 , d t )
x ~ = x + ϵ \tilde x = x + \epsilon x ~ = x + ϵ ϵ ∼ N ( 0 , σ t 2 I ) \epsilon \sim N(0,\sigma_t^2I) ϵ ∼ N ( 0 , σ t 2 I ) d x = g ( t ) d w dx = g(t)dw d x = g ( t ) d w σ t \sigma_t σ t t t t g ( t ) g(t) g ( t )
进一步的为了更好地和g ( t ) g(t) g ( t ) σ t \sigma_t σ t t t t σ ( t ) \sigma(t) σ ( t )
统一表示形式:
模式
Forward SDE Reverse SDE
通用
d x = f ( x , t ) d t + g ( t ) d w \mathrm{d}x = f(x, t) \, \mathrm{d}t + g(t) \, \mathrm{d}w d x = f ( x , t ) d t + g ( t ) d w d x = [ f ( x , t ) − g 2 ( t ) ∇ x log p σ ( x ) ] d t + g ( t ) d w \mathrm{d}x = \left[f(x, t) - g^2(t) \nabla_x \log p_\sigma(x)\right] \, \mathrm{d}t + g(t) \, \mathrm{d}w d x = [ f ( x , t ) − g 2 ( t ) ∇ x log p σ ( x ) ] d t + g ( t ) d w
DDPM
d x = 1 2 β t d t + β t d w dx = \frac{1}{2}\beta_tdt + \sqrt\beta_tdw d x = 2 1 β t d t + β t d w d x = 1 1 − β t ( x t − β t 1 − α ˉ t ϵ θ ( x t , t ) ) + β t z dx = \frac{1}{\sqrt{1 - \beta_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_{\theta}(x_t, t) \right) + \sqrt{\beta_t} z d x = 1 − β t 1 ( x t − 1 − α ˉ t β t ϵ θ ( x t , t ) ) + β t z
SDE link to DDPM
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t|x_{t-1}) = \mathcal N(x_t;\sqrt{1-\beta_t}x_{t-1}, \beta_t I) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I )
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t|x_0) =\mathcal N(x_t; \sqrt{\bar \alpha_t}x_0, (1-\bar \alpha_t)I) q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I )
Forward SDE
x t = 1 − β t x t − 1 + β t ϵ x_t = \sqrt{1 - \beta_t} x_{t-1} + \sqrt\beta_t \epsilon x t = 1 − β t x t − 1 + β t ϵ ϵ ∼ N ( 0 , I ) \epsilon \sim N(0,I) ϵ ∼ N ( 0 , I )
x t − x t − 1 = 1 − β t x t − 1 + β t ϵ − x t − 1 x_t - x_{t-1}= \sqrt{1 - \beta_t} x_{t-1} + \sqrt\beta_t \epsilon - x_{t-1} x t − x t − 1 = 1 − β t x t − 1 + β t ϵ − x t − 1
x t − x t − 1 = ( 1 − 1 2 β t − 1 ) x t − 1 + β t ϵ x_t - x_{t-1} = (1 - \frac{1}{2} \beta_t - 1)x_{t-1} + \sqrt\beta_t \epsilon x t − x t − 1 = ( 1 − 2 1 β t − 1 ) x t − 1 + β t ϵ
x t − x t − 1 = 1 2 β t x t − 1 + β t ϵ x_t - x_{t-1} = \frac{1}{2}\beta_t x_{t-1} + \sqrt\beta_t \epsilon x t − x t − 1 = 2 1 β t x t − 1 + β t ϵ
推导出Forward SDE d x = 1 2 β t d t + β t d w dx = \frac{1}{2}\beta_tdt + \sqrt\beta_tdw d x = 2 1 β t d t + β t d w
Reverse SDE
离散时间步递推x t − 1 = x t + 1 2 β t x t + β t ∇ x log p σ ( x t ) + β t z x_{t-1} = x_t + \frac{1}{2} \beta_t x_t + \beta_t \nabla_x \log p_{\sigma}(x_t) + \sqrt{\beta_t} z x t − 1 = x t + 2 1 β t x t + β t ∇ x log p σ ( x t ) + β t z
分数函数∇ x log p σ ( x ) = ∇ x log p σ ( x t ∣ x 0 ) = − ϵ 1 − α ˉ t = − ϵ θ ( x t , t ) 1 − α ˉ t \nabla_x \log p_\sigma(x)=\nabla_x \log p_\sigma(x_t|x_0) = -\frac{\epsilon}{1-\bar \alpha_t} = -\frac{\epsilon_{\theta}(x_t,t)}{1-\bar \alpha_t} ∇ x log p σ ( x ) = ∇ x log p σ ( x t ∣ x 0 ) = − 1 − α ˉ t ϵ = − 1 − α ˉ t ϵ θ ( x t , t ) x t − 1 = ( 1 + 1 2 β t ) x t − β t 1 − α ˉ t ϵ θ ( x t , t ) + β t z x_{t-1} = \left(1 + \frac{1}{2} \beta_t\right) x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_{\theta}(x_t, t) + \sqrt{\beta_t} z x t − 1 = ( 1 + 2 1 β t ) x t − 1 − α ˉ t β t ϵ θ ( x t , t ) + β t z
利用近似关系1 + 1 2 β t ≈ 1 1 − β t 1 + \frac{1}{2} \beta_t \approx \frac{1}{\sqrt{1 - \beta_t}} 1 + 2 1 β t ≈ 1 − β t 1 x t − 1 = 1 1 − β t x t − β t 1 − α ˉ t ϵ θ ( x t , t ) + β t z x_{t-1} = \frac{1}{\sqrt{1 - \beta_t}} x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_{\theta}(x_t, t) + \sqrt{\beta_t} z x t − 1 = 1 − β t 1 x t − 1 − α ˉ t β t ϵ θ ( x t , t ) + β t z
DDPM Sampler
最终近似为DDPM中采样公式(具体见SCORE-BASED GENERATIVE MODELING中的Appendix E ):x t − 1 = 1 1 − β t ( x t − β t 1 − α ˉ t ϵ θ ( x t , t ) ) + β t z x_{t-1} = \frac{1}{\sqrt{1 - \beta_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_{\theta}(x_t, t) \right) + \sqrt{\beta_t} z x t − 1 = 1 − β t 1 ( x t − 1 − α ˉ t β t ϵ θ ( x t , t ) ) + β t z