[Code] of the project
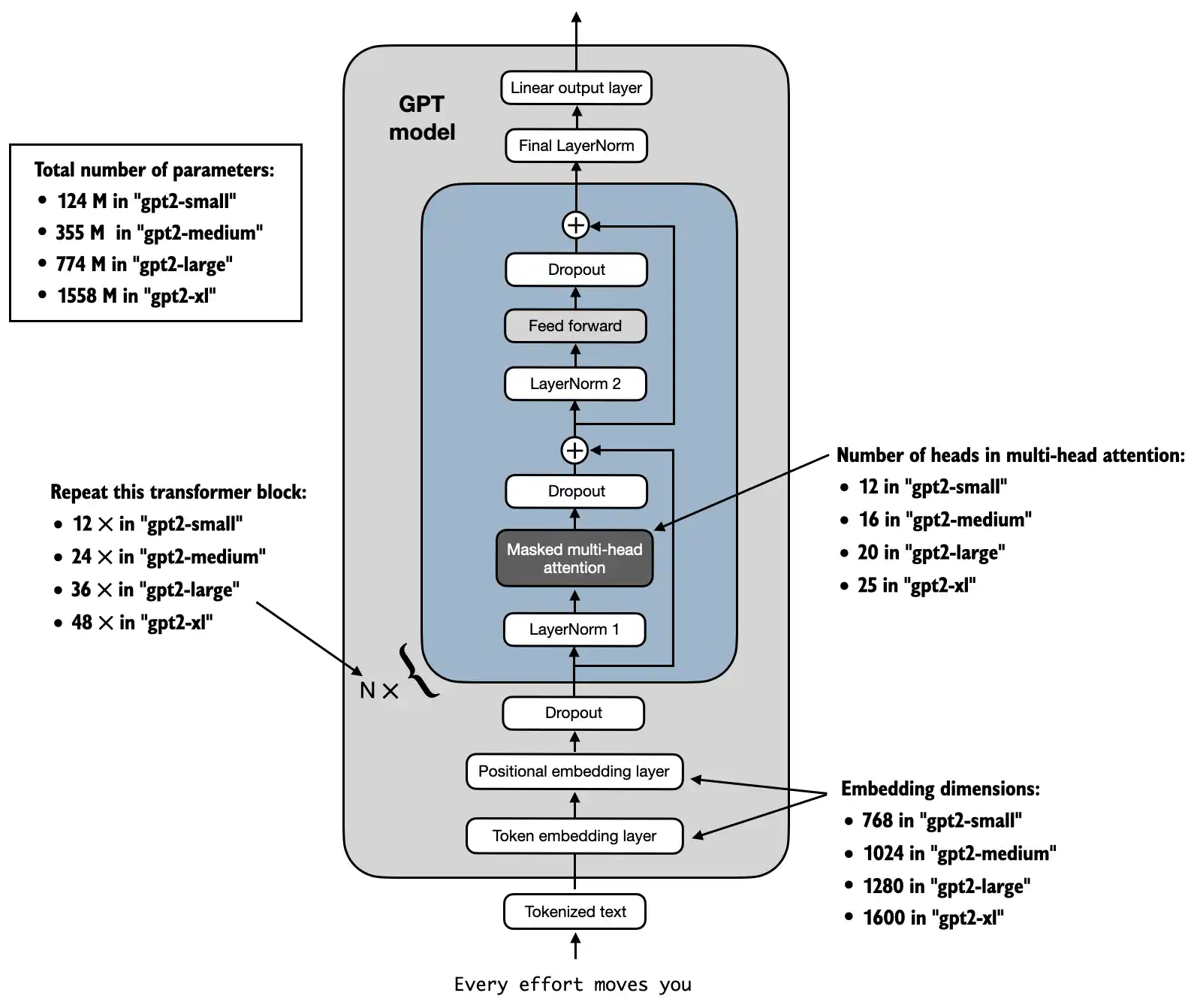
GPT-2架构
本次我们复现的是其124M结构模型 (openai 采用out_head和token_emb层共享参数 )
1 2 3 4 5 6 7 8 9 GPT_CONFIG_124M = {"vocab_size" : 50257 , "context_length" : 1024 , "emb_dim" : 768 , "n_heads" : 12 , "n_layers" : 12 , "drop_rate" : 0.1 , "qkv_bias" : False
GPTModel
tokenizer
transformer block * n
out_head
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class GPTModel (nn.Module):def __init__ (self, cfg ):super ().__init__()"vocab_size" ], cfg["emb_dim" ])"context_length" ], cfg["emb_dim" ])"drop_rate" ])for _ in range (cfg["n_layers" ])])"emb_dim" ])"emb_dim" ], cfg["vocab_size" ], bias=False )def _init_weights (self, module ):if isinstance (module, nn.Linear):0.02 if hasattr (module, 'NANOGPT_SCALE_INIT' ):2 * self.cfg["n_layers" ]) ** -0.5 0.0 , std=std)if module.bias is not None :elif isinstance (module, nn.Embedding):0.0 , std=0.02 )def forward (self, in_idx ):return logits
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class TransformerBlock (nn.Module):def __init__ (self, cfg ):super ().__init__()"emb_dim" ],"emb_dim" ],"context_length" ],"n_heads" ],"drop_rate" ],"qkv_bias" ])"emb_dim" ])"emb_dim" ])"drop_rate" ])def forward (self, x ):return x
Layernorm:
1 2 3 4 5 6 7 8 9 10 11 12 class LayerNorm (nn.Module):def __init__ (self, emb_dim ):super ().__init__()1e-5 def forward (self, x ):1 , keepdim=True )1 , keepdim=True , unbiased=False )return self.scale * norm_x + self.shift
Gelu:
1 2 3 4 5 6 7 8 9 class GELU (nn.Module):def __init__ (self ):super ().__init__()def forward (self, x ):return 0.5 * x * (1 + torch.tanh(2.0 / torch.pi)) *0.044715 * torch.pow (x, 3 ))
其中前向传播网络由三层组成:
1 2 3 4 5 6 7 8 9 10 11 12 class FeedForward (nn.Module):def __init__ (self, cfg ):super ().__init__()"emb_dim" ], 4 * cfg["emb_dim" ]),4 * cfg["emb_dim" ], cfg["emb_dim" ]),1 ].NANOGPT_SCALE_INIT = True def forward (self, x ):return self.layers(x)
注意:NANOGPT_SCALE_INIT = True是为了与openai初始化权重时一致而添加的一个特殊标志位,下节会具体讲解
多头注意力:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class MultiHeadAttention (nn.Module):def __init__ (self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False ):super ().__init__()assert d_out % num_heads == 0 , "d_out must be divisible by n_heads" True 'mask' , torch.triu(torch.ones(context_length, context_length), diagonal=1 ))def forward (self, x ):1 , 2 )1 , 2 )1 , 2 )2 , 3 ) bool ()[:num_tokens, :num_tokens]1 ]**0.5 , dim=-1 )1 , 2 )return context_vec
至此,GPT-2的整个架构已经实现完毕啦
Training Techs
掌握训练模型时的必备技巧不仅能大大提高训练速度,也能助于提升性能
权重初始化(_init_weights)
权重初始化一般符合正态分布,均值u u u σ \sigma σ 1 D i m e n s i o n = 1 768 = 0.036 \frac{1}{\sqrt{Dimension}}= \frac{1}{\sqrt{768}}=0.036 D im e n s i o n 1 = 768 1 = 0.036
对于有残差的网络模块,通常会额外增加一个乘积因子1 N \frac{1}{N} N 1 1 N ∗ D i m e n s i o n \frac{1}{N*Dimension} N ∗ D im e n s i o n 1
如下有个很好地解释
1 2 3 4 5 x = torch.zeros(768 )100 for i in range (n):768 ) print (x.std())
你会发现x从最初的0,增长到了100 \sqrt{100} 100 ϵ ∼ N ( 0 , 1 ) \epsilon ∼N(0,1) ϵ ∼ N ( 0 , 1 )
根据方差的线性性质:
Var ( x i ) = Var ( ∑ j = 1 n z i , j ) = ∑ j = 1 n Var ( z i , j ) = n \begin{align*}
\text{Var}(x_i) &= \text{Var}\left(\sum_{j=1}^{n} z_{i,j}\right) \\
&= \sum_{j=1}^{n} \text{Var}(z_{i,j}) \\
&= n
\end{align*}
Var ( x i ) = Var ( j = 1 ∑ n z i , j ) = j = 1 ∑ n Var ( z i , j ) = n
因此,x 的标准差为:
s t d ( x ) = n std(x)= \sqrt{n} s t d ( x ) = n
故对于残差网络层(见上图TransfomerBlock架构,实际上就是多头注意力的最后一层和FFN的最后一层),我们需要额外设置因子来初始化权重。(2 * self.cfg["n_layers"]是因为一个transformerblock中有两个残差次数)
1 2 if hasattr (module, 'NANOGPT_SCALE_INIT' ):2 * self.cfg["n_layers" ]) ** -0.5
混合精度训练(Mixed Precision Training)
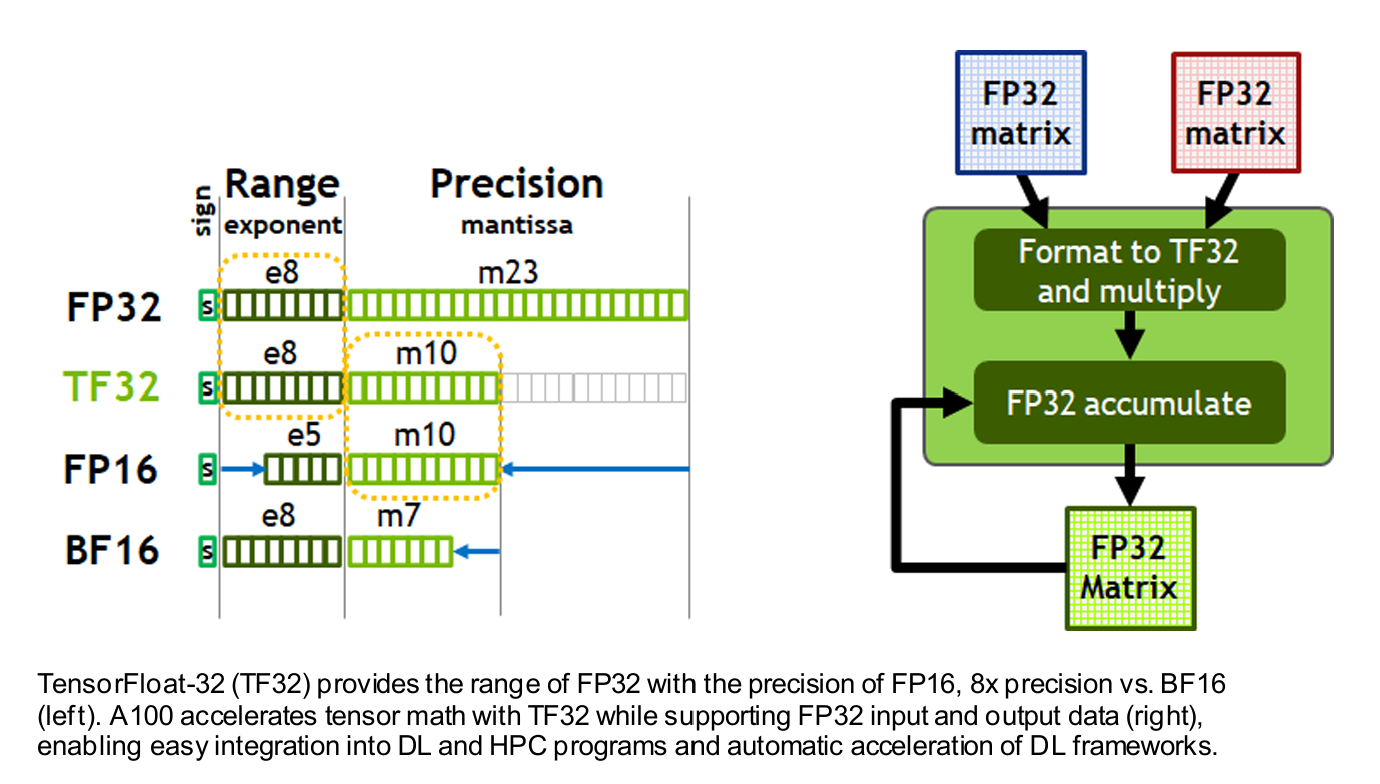
Nvidia官方详解:Nvidia-ampere-architecture-whitepaper
TF32在内存中保持32位,计算时被裁剪精度降低
BF16则在内存和计算中都使用16位
混合精度训练的核心思想是利用 低精度 (如 bfloat16 或 float16)来加速计算,同时利用 高精度 (如 float32)来存储权重,保持模型训练的稳定性。
默认地torch采用fp32精度, 虽然保持最高的精度,但导致训练速度很慢,且实际使用中没有必要使用fp32来训练。具体来讲,我们的输入,输出,权重都为fp32保持不变,但我们希望在训练时候的激活和权重尽量减小来提高训练速度。
torch.set_float32_matmul_precision(precision)
“highest”:
“high”:
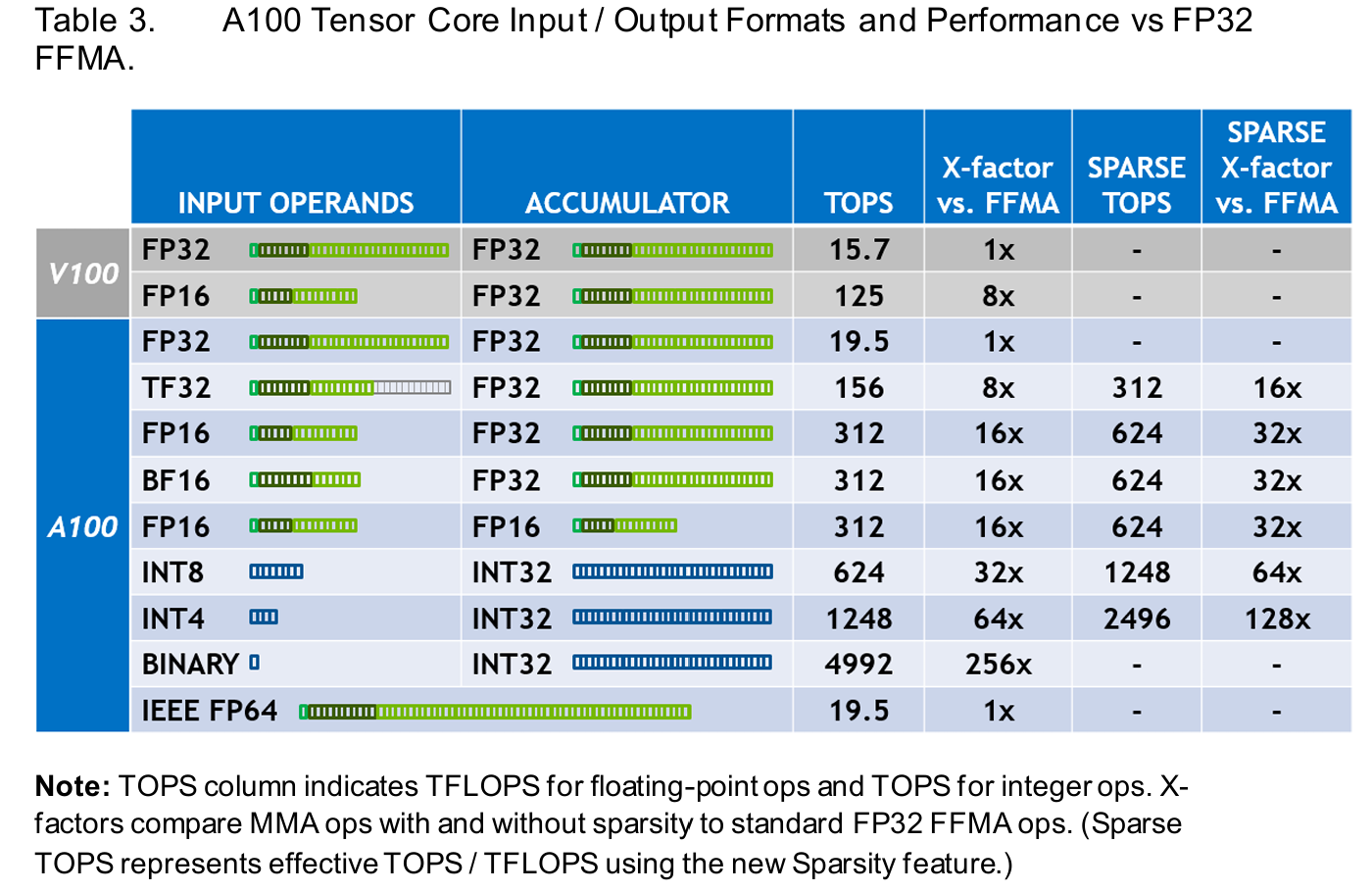
TensorFloat32 数据类型 (速度最大相比fp32可x8, 但实际碍于内存速率测试x3左右)或如果可用的快速矩阵乘法算法支持,可能会使用将 float32 视为两个 bfloat16 数字的和的策略
“medium”:
bfloat16 数据类型进行矩阵乘法的内部计算(速度最大相比fp32可x16, 实际速度x3.5左右)
仅需额外增加一行代码,其他无需做任何修改。模型的权重都是fp32存储,不会改变,但计算矩阵乘积 的时候却变为tf32,免费地大大提高训练速度!(该设置仅针对矩阵乘积有效)
代码示例:
1 2 3 4 5 6 7 torch.set_float32_matmul_precision("high" )for epoch in range (epochs):
autocasting
使用方式:将前向传播过程的计算logits和loss两个过程使用autocast包裹,backward使用默认精度反向传播
1 2 3 4 5 with torch.autocast(device_type=device_type, dtype=torch.bfloat16): input )1 , logits.size(-1 )),target.view(-1 ))
实测比torch.set_float32_matmul_precision(precision)快一些
Torch.compile
默认情况下必须使用的技术
1 2 3 model = GPTModel(GPT_CONFIG_124M)compile (model)
除非是debug,不然不用白不用,该项目中实测提升速度x3
Flashattention
默认情况下必须使用的技术 ,除非对于attention本身运算过程有所修改
torch.nn.Functional.scaled_dot_product_attention(queries, keys, values, is_causal=True, dropout_p=self.dropout_p)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class MultiHeadAttention (nn.Module):def __init__ (self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False ):super ().__init__()assert d_out % num_heads == 0 , "d_out must be divisible by n_heads" True 'mask' , torch.triu(torch.ones(context_length, context_length), diagonal=1 ))def forward (self, x ):1 , 2 )1 , 2 )1 , 2 )True , dropout_p=self.dropout_p)1 , 2 ).contiguous().view(b, num_tokens, self.d_out)return context_vec
Lr scheduler
lr scheduler是调控学习率来提高模型的性能重要手段
warm up
warm up的step一般为total_step的0.1%到20%
1 2 if it < configs.warmup_steps:return configs.max_lr * (it+1 ) / configs.warmup_steps
cosine decay
c o e f f = 0.5 × ( 1.0 + c o s ( π × d e c a y r a t i o ) ) coeff=0.5×(1.0+cos(π×decay_{ratio}))
coe ff = 0.5 × ( 1.0 + cos ( π × d ec a y r a t i o ))
这个函数确保 coeff 从 1 开始,到训练结束时降到 0。
l r = m i n l r + c o e f f × ( m a x l r − m i n l r ) lr=minlr+coeff×(maxlr−minlr)
l r = min l r + coe ff × ( ma x l r − min l r )
1 2 3 4 5 assert 0 <= decay_ratio <= 1 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) return configs.min_lr + coeff * (configs.max_lr - configs.min_lr)
最终:
1 2 3 4 5 6 7 8 9 10 11 12 def get_lr (it, configs ):if it < configs.warmup_steps:return configs.max_lr * (it+1 ) / configs.warmup_stepsif it > configs.max_steps:return configs.min_lrassert 0 <= decay_ratio <= 1 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) return configs.min_lr + coeff * (configs.max_lr - configs.min_lr)
Distributed Data Parallel (DDP) for multiple GPUs training
torchrun 是 PyTorch 提供的一个命令行工具,用于启动和管理分布式训练
torchrun会自动初始化分布式环境,并为每个进程分配一个 rank 和 local_rank。除了rank不同,执行的代码完全一致。这些信息可以在代码中通过 os.environ['RANK'] 和 os.environ['LOCAL_RANK'] 获取。
rank: 进程全局内独特的标号
local_rank: 进程在当前节点局部内的标号, 如果只有一个节点,那local_rank 和rank相等
world_size:总进程数量
终端命令行
单节点运行:
1 2 3 4 5 torchrun$NUM_TRAINERS
--standalone 使得分布式训练在单节点环境下运行,所有训练进程都在同一个节点上启动,而不需要通过多个节点进行通信。--nnodes=1 表示只有一个节点参与训练。--nproc-per-node 表示每个节点上启动的进程数。通常情况下,每个进程会绑定一个 GPU,所以 NUM_TRAINERS 通常等于要使用的 GPU 数量。
单节点多任务以及多节点运行查看torchrun官方文档
DDP代码过程
初始化进程
在使用torchrun多GPU训练的代码中,第一步首先应该获取由torchrun传递的,当前进程的标识号rank,local_rank, 以及world_size。
保证cuda可用后,使用 init_process_group(backend="nccl", rank=rank, world_size=world_size)初始化分布式进程组
设置主进程以及当前进程的device
1 2 3 4 5 6 7 8 9 10 11 12 13 ddp_rank = int (os.environ.get('RANK' , 0 ))int (os.environ['LOCAL_RANK' ])int (os.environ.get('WORLD_SIZE' , 1 ))assert torch.cuda.is_available(), "for now we need CUDA for DDP" "nccl" , rank=rank, world_size=world_size)0 f'cuda:{ddp_local_rank} ' "cuda" if device.startswith("cuda" ) else "cpu"
将model使用DDP包裹 , 同时保存原有的raw_model
1 2 3 from torch.nn.parallel import DistributedDataParallel as DDP
pytorch官方的文档对device_ids解释不清,但Andrej Karpathy 很明确就是ddp_local_rank
DDP的作用: 将每个节点每个step的loss.backward()反向传播同步,汇总求平均,每个节点保留平均梯度最后更新参数
但在本项目的实现中由于引进了grad_accum_steps, 希望loss累积不断addgrad_accum_steps后才进行梯度更新,因此需要额外利用require_backward_grad_sync控制DDP的梯度更新
对于原模型的保存,如果使用torch.compile,要在调用前就保存raw_model,否则参数名会带有前缀_orig_mod
1 2 3 4 5 6 7 8 9 10 11 12 13 for step in range (max_steps):for micro_step in range (grad_accum_steps):1 )input , target = train_loader.next_batch()input , target = input .to(device), target.to(device)input )1 , logits.size(-1 )), target.view(-1 ))
分布式训练保存权重的方式
1 torch.save(raw_model.state_dict(), 'best_model.pth' )
必须使用原模型保存权重,这样下次才能使用单卡GPU加载模型,而不是DDP多GPU加载
训练结束释放分布式进程组
References