RL1 MDP
基础概念
-
State: agent代理与环境交互时的状态
- state space: 即所有状态组成的集合
-
Action: 给定一个状态下所能采取的行动
- Action space of a state: 给定一个状态下所能采取的所有行动组成的集合
-
State Transition:形如 ,在状态 采取行动 转移到状态
-
State transition probability: 状态转移概率,在一个状态采取行动a转移后的状态可能是不确定的
-
离散的(确定的情况):
-
随机的(符合一定的概率分布)
-
-
Policy: 描述在一个状态所能采取的行动分布
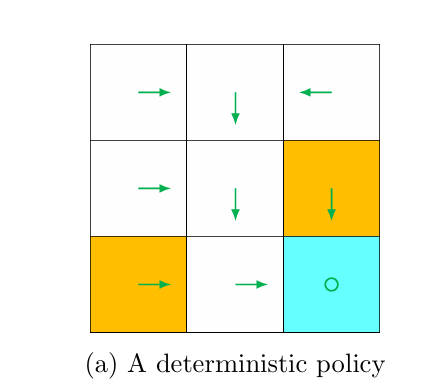
-
Reward:在状态采取行动会获得一定的奖励,注意奖励只跟当前状态和采取的行动有关,和下一刻转移到的状态无关。十分易错。与上方的状态转移概率相同,奖励也是服从一定分布的
and
-
Trajectory : a state-action-reward chain
- Return of a trajectory:将trajectory链上所获得奖励计算总和
- 然而trajectory可能是无限长的,因此通常会在计算return时增加折扣因子discount rate , 折扣因子决定了智能体更关注短期奖励还是长期奖励
- :智能体只关心当前奖励,忽略未来奖励。
- :智能体平等对待当前和未来的所有奖励。
- :智能体更重视近期奖励,同时也会考虑远期奖励(但远期奖励的权重会逐渐减小)。
- 折扣回报公式:
- Episode(or a trial): 智能体(Agent)在环境中按照某个策略(Policy)进行交互,直到到达某个终止状态(Terminal State)就停止的完整轨迹。
- 由终止状态的任务称为 episodic tasks
- 无终止状态的任务称为 continuing tasks
Markov decision process (MDP)
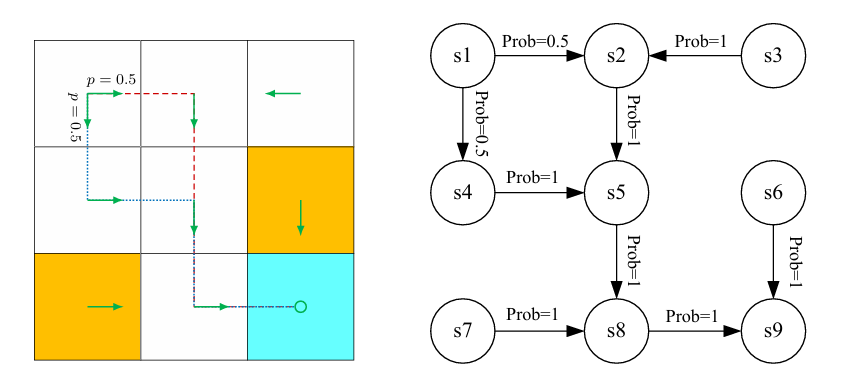
1. 集合(Sets)
- 状态(State):状态集合 。
- 动作(Action):在状态 下,可用的动作集合 。
- 奖励(Reward):在状态 下采取动作 后,可能获得的奖励集合 。
2. 概率分布(Probability Distributions)
-
状态转移概率(State Transition Probability):
- 在状态 下采取动作 ,转移到状态 的概率为:
- 在状态 下采取动作 ,转移到状态 的概率为:
-
奖励概率(Reward Probability):
- 在状态 下采取动作 ,获得奖励 的概率为:
- 在状态 下采取动作 ,获得奖励 的概率为:
3. 策略(Policy)
- 在状态 下,选择动作 的概率为:
4. 马尔可夫性质(Markov Property)
-
无记忆性(Memoryless Property):
-
下一个状态 和奖励 只依赖于当前状态 和动作 ,而与之前的状态和动作无关。
-
数学表示为:
-
5. MDP 框架
- 所有上述概念都可以放在 MDP 框架中:
- 状态、动作、奖励 是 MDP 的基本组成部分。
- 状态转移概率 和 奖励概率 定义了环境的动态特性。
- 策略 是智能体的行为规则。
- 马尔可夫性质 是 MDP 的核心假设,简化了问题的复杂性。
RL1 MDP
https://xrlexpert.github.io/2025/02/12/RL1/