回顾
折扣回报公式:
Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1
可以帮助我们们衡量一个策略的好与坏,G更大的代表策略也更优。下面我们具体讲讲如何计算Gt
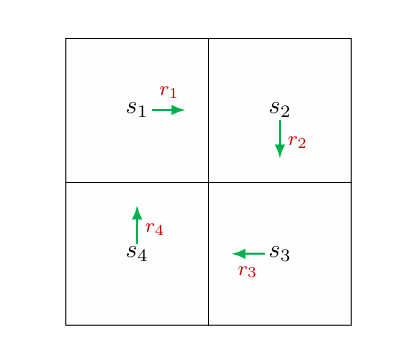
Method1:按照定义计算
v1v2v3v4=r1+γr2+γ2r3+...=r2+γr3+γ2r4+...=r3+γr4+γ2r1+...=r4+γr1+γ2r2+...
Method2:按照价值函数计算
v1v2v3v4=r1+γv2=r2+γv3=r3+γv4=r4+γv1
上述等式可以进一步写为矩阵的形式
v1v2v3v4=r1r2r3r4+γ0001100001000010v1v2v3v4
对应的矩阵形式为:
V=R+γPV
其中:
- V=v1v2v3v4:状态值函数的向量。
- R=r1r2r3r4:即时奖励的向量。
- P=0001100001000010:状态转移概率矩阵。
- γ:折扣因子。
最终的解为:
V=(I−γP)−1R
状态价值(State Value)
数学公式
状态值函数 vπ(s) 定义为从状态 s 开始,遵循策略 π 的期望回报(Expected Return):
vπ(s)=E[Gt∣St=s]
其中:
- Gt 是从时间步 t 开始的折扣回报(Discounted Return)。
- St=s 表示当前状态为 s。
- E 表示期望值。
下面给出计算状态价值函数的推导
vπ(s)=E[Gt∣St=s]=E[Rt∣St=S]+γE[Gt+1∣St=s]=π(a∣s)a∑p(r∣s,a)r+γ⋅ π(a∣s)s′∑p(s′∣s,a)vπ(s′)=π(a∣s)[a∑p(r∣s,a)r+γ⋅s′∑p(s′∣s,a)vπ(s′)]=rπ(s)+γs′∑pπ(s′∣s)vπ(s′)
写成矩阵形式:
vπ=rπ+γPπvπ
数值求解
vπ的closed-form(有限个标准数学运算)求解:
vπ=(I−γPπ)−1rπ
实际上,我们通常采用迭代算法计算
vk+1=rπ+γPπvk
算法正确性证明:
定义误差为δk=vk−vπ。
我们只需要证明δk→0。
将vk+1=δk+1+vπ和vk=δk+vπ代入方程vk+1=rπ+γPπvk,得到:
δk+1+vπ=rπ+γPπ(δk+vπ),
可以改写为:
δk+1=−vπ+rπ+γPπδk+γPπvπ
=γPπδk−vπ+(rπ+γPπvπ)
=γPπδk.
结果为:
δk+1=γPπδk=γ2Pπ2δk−1=⋯=γk+1Pπk+1δ0.
由于Pπ的每个条目都不小于0且不大于1,我们有0≤Pπk≤1,对于任何k都成立。
即Pπk的每个条目都不大于1。另一方面,由于γ<1,我们知道γk→0,因此δk+1=γk+1Pπk+1δ0→0当k→∞时。
行动价值(Action Value)
q(s,a)=E[Gt∣St=s,At=a]
联系上述的状态价值公式
vπ(s)=π(a∣s)a∑q(s,a)
不难得到行动价值公式
q(s,a)=a∑p(r∣s,a)r+γ⋅s′∑p(s′∣s,a)vπ(s′)
- 状态价值:已知行动价值计算状态价值
- 行动价值:已知未来的状态价值计算当前的行动价值