回顾
上一讲中BOE解法实际上被称为值迭代算法(Value iteration algorithm)
值迭代算法(Value iteration algorithm)
该算法实际上就是两步:
-
第一步 Policy update:
πk+1(a∣s)={10当 a=ak∗(s)当 a=ak∗(s)
-
第二步 Value update:
vk+1=rk+1+Pπk+1vk=qk(s,a)
-
注意迭代过程中每一步的vk 实际上并不是贝尔曼公式中的状态价值,而是一个中间计算值,不具备物理含义
策略迭代算法 (Policy iteration algorithm)
该算法实际上也是两步:
-
第一步 Policy evaluation:
vk=rπk+γPπkvk
-
第二步 Policy improvement:
πk+1=argmaxπ(rπk+γPπkvk)
-
注意这里第一步是贝尔曼公式,这里的vk不同于值迭代算法,是真正的状态价值。
-
第一步的贝尔曼公式的求解相当于又嵌套了一层迭代循环
算法正确性证明:
首先证明:
If πk+1=argmaxπ(rπk+γPπkvπk), then vπk+1≥vπk. Here, vπk+1≥vπk means that vπk+1(s)≥vπk(s) for all s.
已知满足贝尔曼公式
vπk=rπk+γPπkvπkvπk+1=rπk+1+γPπk+1vπk+1
已知 πk+1=argmaxπ(rπk+γPπk+1vπk),
所以rπk+1+γPπk+1vπk≥rπk+γPπkvπk
故
vπk−vπk+1≤rπk+1+γPπk+1vπk−rπk+1+γPπk+1vπk+1≤γPπk+1(vπk−vπk+1)≤...≤γnPπk+1n(vπk−vπk+1)≤n→∞limγnPπk+1n(vπk−vπk+1)=0
极限的存在是因为 limn→∞γn=0,并且对于任何 n,Pπk+1n 是一个非负的随机矩阵。
随机矩阵(stochastic matrix)是一种特殊类型的矩阵,它具有以下两个主要特征:
- 非负元素:矩阵中的每个元素都大于或等于零,即矩阵的元素不能是负数。
- 每行的元素之和为1:矩阵中每一行的所有元素的和等于1。这个特性保证了矩阵的每一行代表一个概率分布,因为概率的和必须为1。
因此 {vπ0,vπ1,...vπk}是一个单调递增的数列
又因为存在v∗≥v 对于任意的v, 根据单调递增数列必定收敛定理,上述算法最终一定收敛到v∗
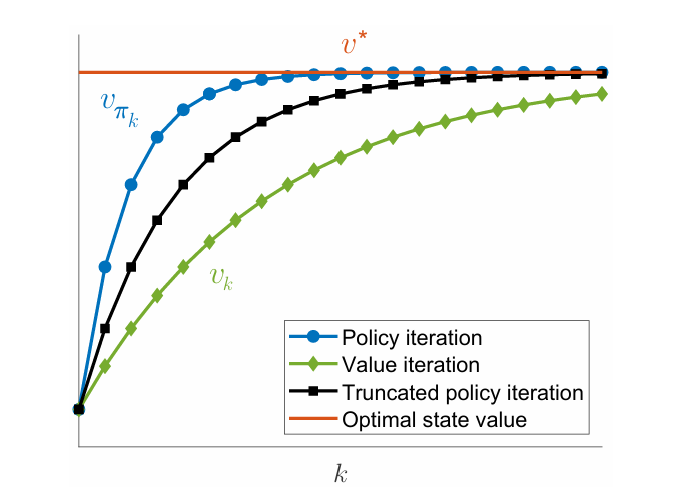
二者比较
不难发现:值迭代算法上是策略迭代算法的退化版
- 值迭代算法:在value update时只进行一步预测
- 策略迭代算法:在value update时直到求解出真正的状态价值后才停止预测
Policy iteration:Value iteration:π0PEvπ0PIπ1PEvπ1PIπ2PE⋯v0PUπ1′VUv1PUπ2′VUv2PU⋯
故实际上存在二者中间的普适算法,称为中间跌断迭代算法Truncated policy iteration algorithm
即在value update时迭代j步,j为自定义超参数
MC Basic算法
上述算法都属于Model based算法,真实的概率分布均已知
Policy 算法需要已知 p(r∣s,a),p(s′∣s,a),来求解出状态价值,之后再进行policy的优化
如果我们不能已知p(r∣s,a),p(s′∣s,a)的model,那该如何计算?
注意这里是不知道model具体的概率分布,但我们还是可以和model交互得到状态转移和奖励
这就属于Model free算法,即只有数据,而没有这些数据的真实分布。
蒙特卡罗(Monte Carlo)basic算法即利用大数定律,利用数据进行对动作状态价值做Mean estimation
已知当前的策略π 后,选择每一对(s,a)根据当前策略模拟大量episode (单个episode的长度理论上越长越好),求return,最后计算平均,对动作状态价值进行更新,最后通过贪婪或者ϵ−greedy 得到最优策略
qπk(s,a)=E[Gt∣St=s,At=a]≈n1i=1∑ngπk(i)(s,a).
MC Exploring Starts算法
朴素的MC Basic算法很低效:
- 一个episode只用于一个(s,a)的估计
考虑如下的一段episode:
s1a2s2a4s1a2s2a3s5a1…()
事实上可以为(s1,a2), (s2,a4), (s2,a3) …多个对进行估计
其中有两种形式
- every visit: 一条episode由前往后,对于每个(s,a)都用剩下的episode进行估计
- first visit:一条episode由前往后,遇到之前未出现过的(s,a)都用剩下的episode进行估计
- 等收集到所有episode后才更新policy
可以类似梯度下降一样,收集到一个episode就更新一次
针对以上两点MC Exploring Starts对此做了优化

- 其中exploring starts条件意为初始(s0,a0)要保证所有状态动作对都可能被访问到
MC ϵ-Greedy
MC Basic 和 Mc Exploring Starts都需要对(s,a)有良好的估计和探索,然而使用确定的策略(即每个状态下只有一个可能的动作)对该估计有较大限制,MC ϵ-Greedy采用soft policy来解决该问题
具体而言,基于MC Exploring Starts,MC ϵ-Greedy将policy improvement中的完全贪心形式改为:
πk+1(a∣s)=⎩⎨⎧1−∣A(s)∣∣A(s)∣−1ϵ,∣A(s)∣1ϵ,a=ak∗,a=ak∗.
- 其中ϵ∈[0,1], ∣A(S)∣ 是该状态下可能的所有动作的数量
- 既保证行动价值最高的策略施行概率大(greedy)
- 也保证了每个动作都可能被执行(explore)
算法流程:

一个重要的结论:
当ϵ较小时,MC ϵ-Greedy所得到的optimal ϵ-Greedy Policy与最优的greedy Policy能够保持consistent,即ϵ-Greedy Policy中概率最大的行动对应于greedy Policy中概率=1的行动(但当ϵ如何较大,最终得到的策略可能不于最优策略保持一致)
- 因此在实际部署时,我们还需要将ϵ-Greedy Policy转化为greedy Policy来得到最优策略